Introduction to Web Scraping
What Is Web Scraping and Why Is It Useful?
So far when it comes to working with the web, you have been creating your own HTML pages and hosting them via GitHub. But we can also use Python to interact with the web in a different way: by scraping data from web pages. The data we extract is exactly the same as what you have been writing, so elements like headers, paragraphs, and links, etc.
Web Scraping for Preservation
Web scraping is also what we use to preserve the web. Remember the Wayback Machine? That’s a web archive that uses web scraping to save web pages. The way it works is that it uses a web crawler to find links to web pages and then it uses web scraping to save the content of those pages.
Is Web Scraping Legal or Ethical?
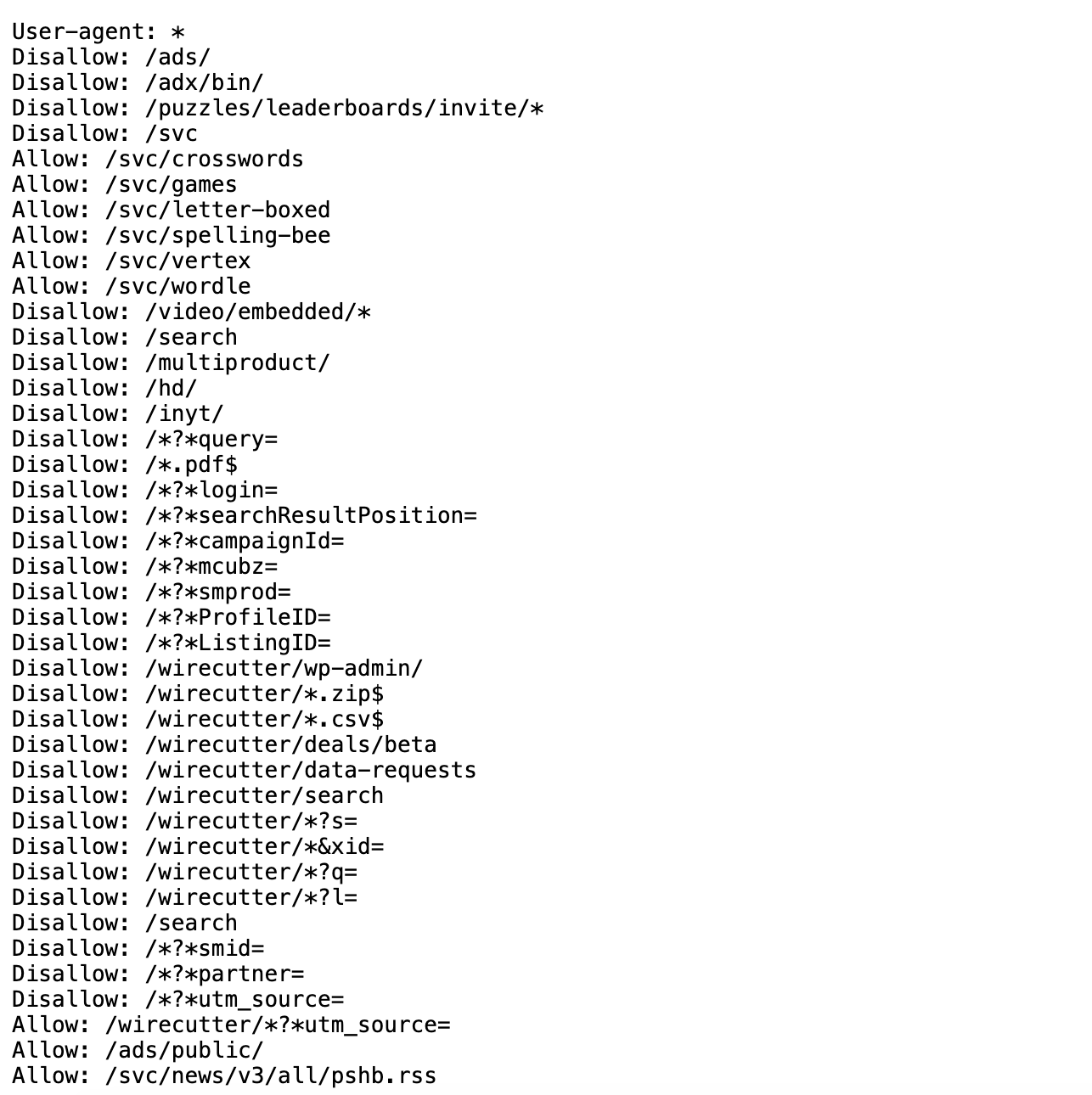
In terms of ethics, web scraping can be a bit of a grey area. It’s generally considered ethical to scrape publicly available data, but it’s not ethical to scrape data from a website that has a terms of service that prohibits scraping. It can be difficult to find those terms of service, but one more obvious example of a website banning scraping is if it prohibits scraping in its robots.txt file. A robots.txt file is a file that websites use to tell web crawlers which pages they are allowed to scrape.
Guidelines for Web Scraping
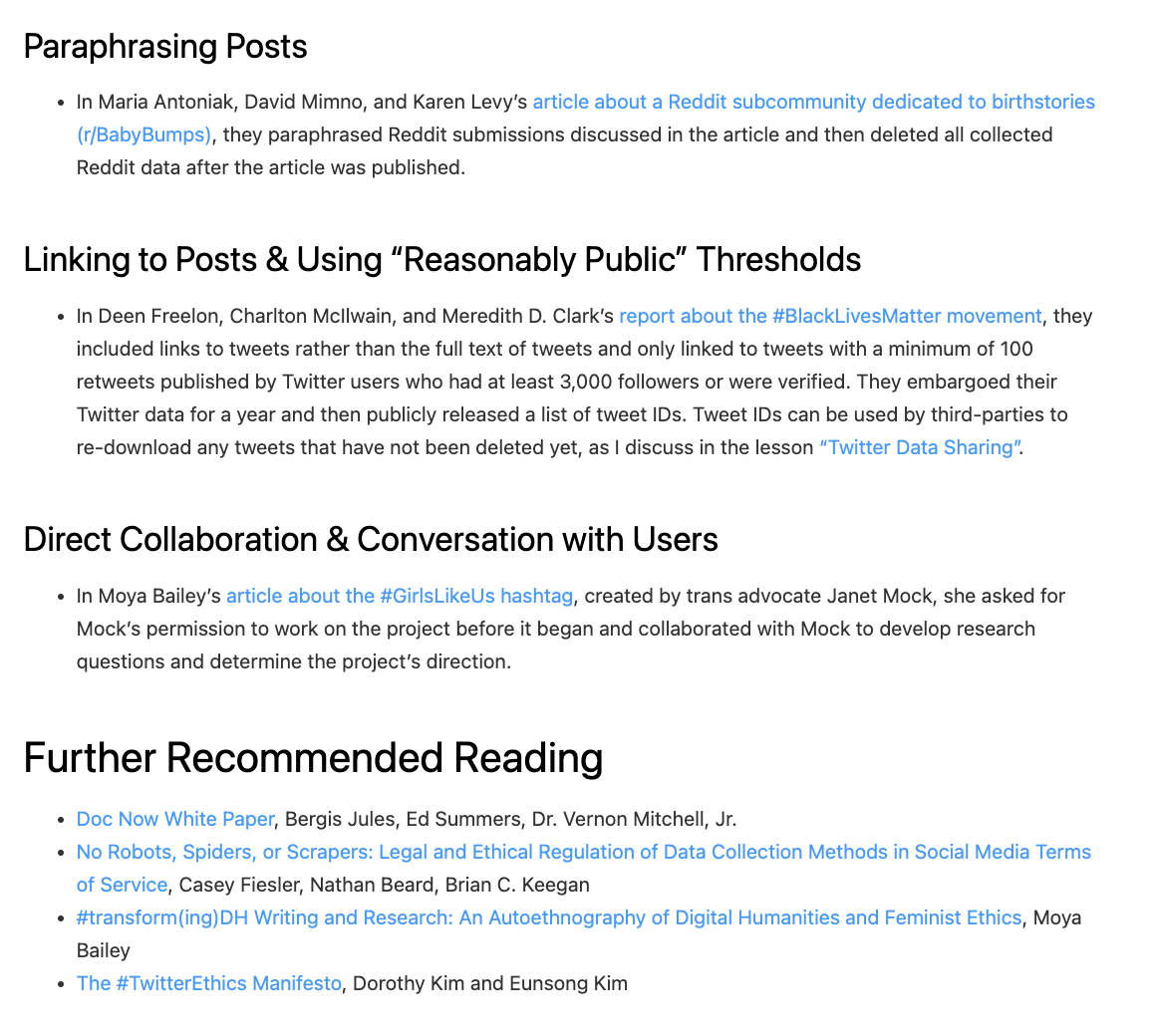
As you can see above, Walsh also has a great overview of different strategies and resources for this type of work, so highly recommend visiting the original chapter to explore these further in depth https://melaniewalsh.github.io/Intro-Cultural-Analytics/04-Data-Collection/01-User-Ethics-Legal-Concerns.html.
Import Error
You’ll likely see the following error if you try to run this code:
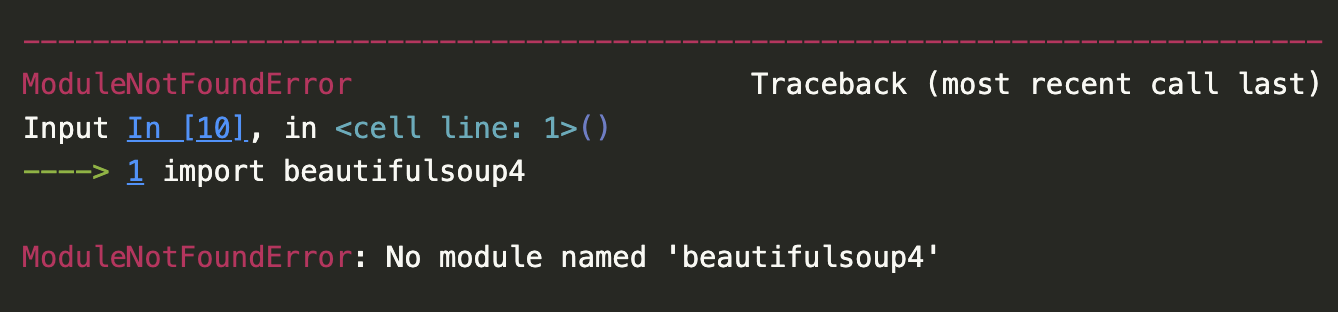
A screenshot of the error when trying to import beautifulsoup4.
BeautifulSoup Documentation
But this is a great example of why we always want to read the documentation, which is available here https://www.crummy.com/software/BeautifulSoup/bs4/doc/.
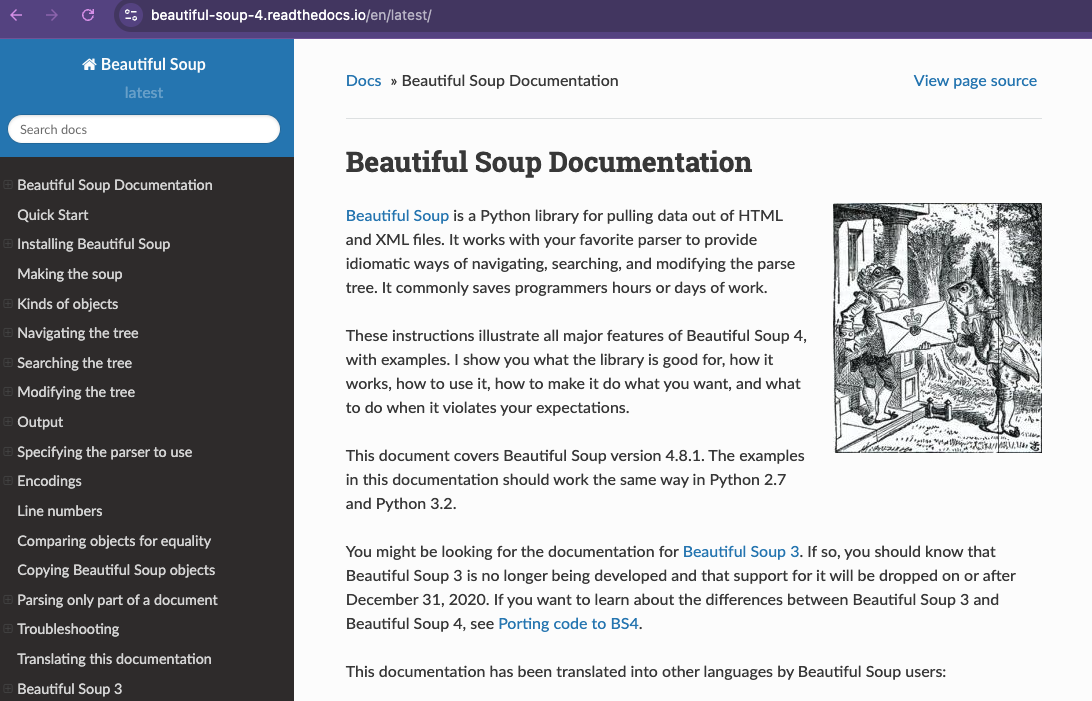
A screenshot of the BeautifulSoup documentation.
Scraping Project Gutenberg
So far we’ve been using some fairly basic HTML but we can start working with an actual HTML document. Today we’ll be using Project Gutenberg’s Top 100 eBooks page. This page lists the top 100 eBooks on Project Gutenberg and we can use BeautifulSoup to scrape the titles.
First, we’re going to save the page as an HTML file. You can do this by right clicking on the page and selecting “Save As” and then saving it as top_100_ebooks.html.
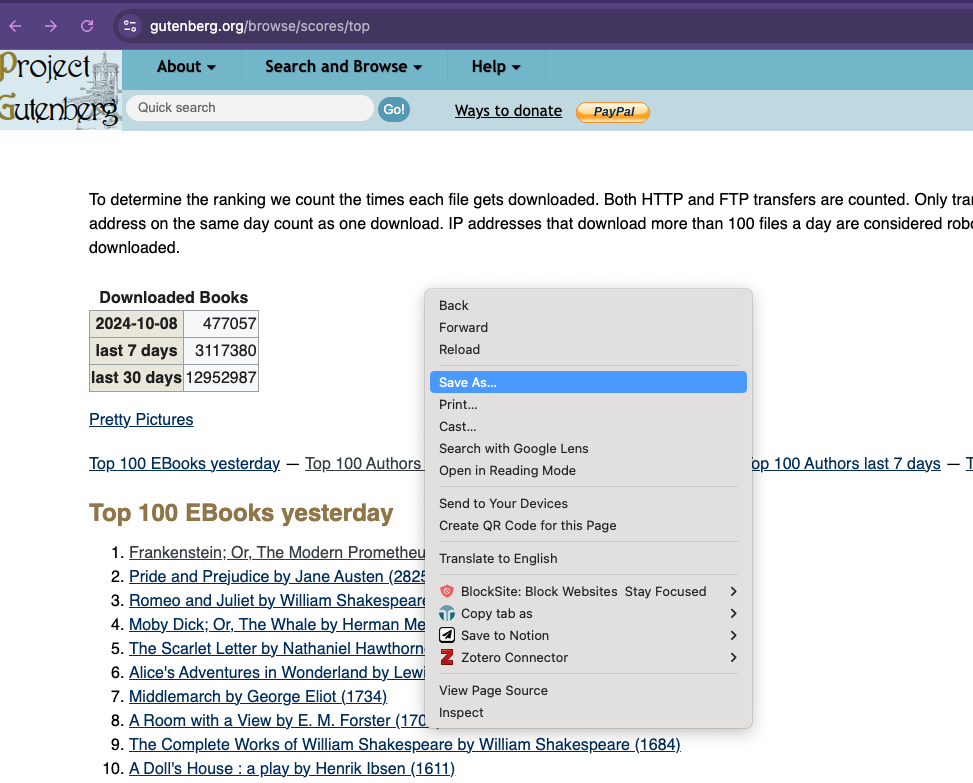
Inspecting the HTML
First, let’s take a look at the structure of the HTML document. We can use the inspect feature in your browser to do this. We can see that Top 100 EBooks yesterday is an h2 tag.
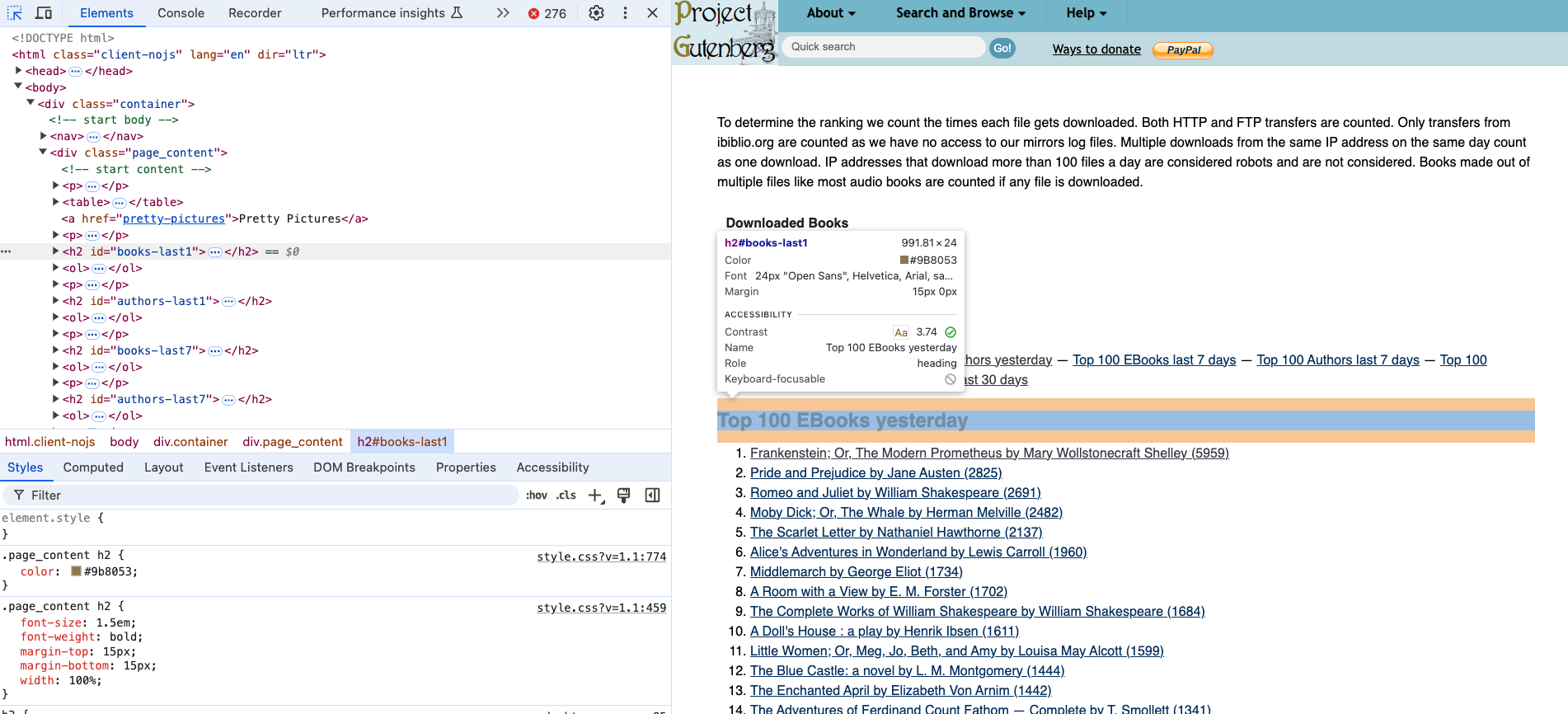
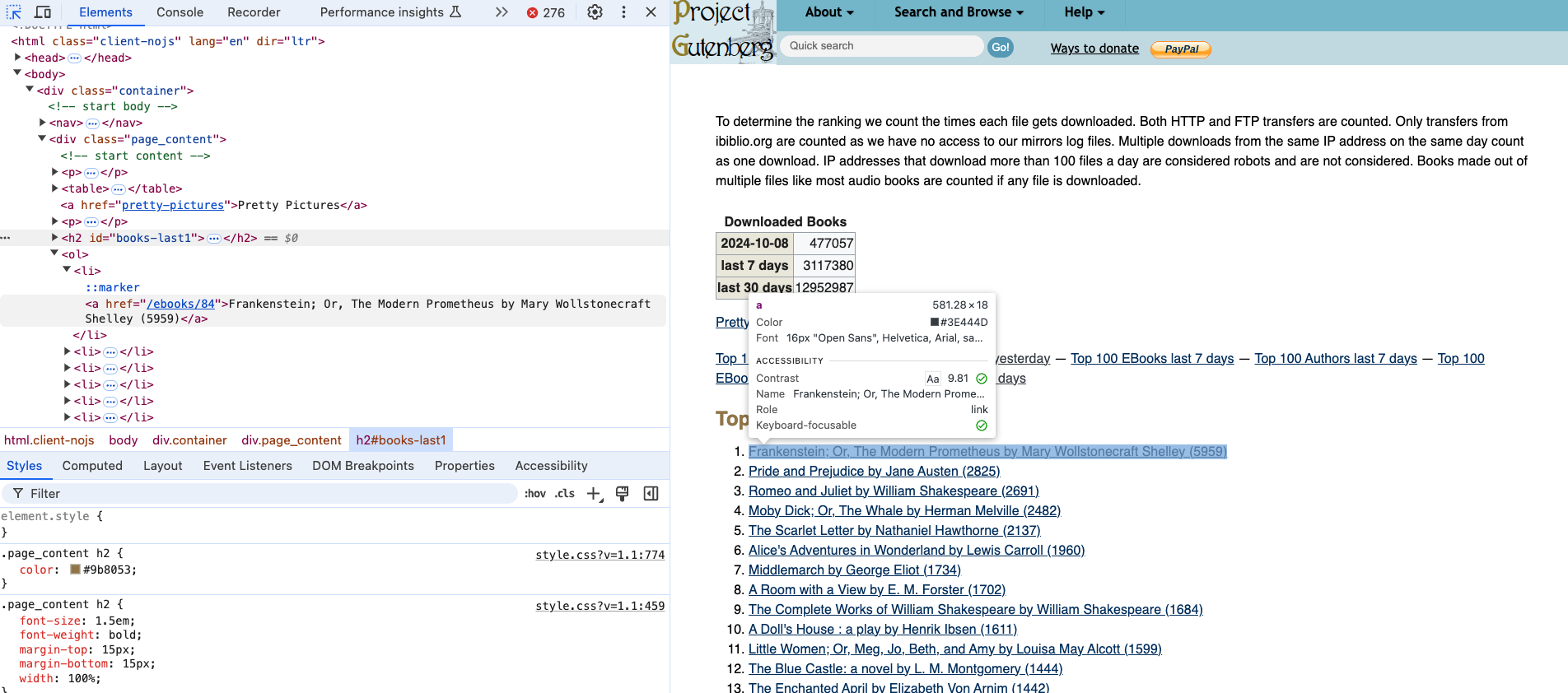
Finding the Book Titles
If we select the titles, we can see that they are nested in an ol tag and then each title is in a li tag. So we can use the find_all() method to get all the li tags and then use get_text() to extract the text.
Advanced Web Scraping
Now that we have the basics down, let’s look at scraping more complex websites. Many fan wikis and community-created wikis contain rich data that can be useful for research.
For example, Wookieepedia is the Star Wars wiki with over 150,000 articles! There are many fandom wikis across different fandoms and communities.
Checking robots.txt
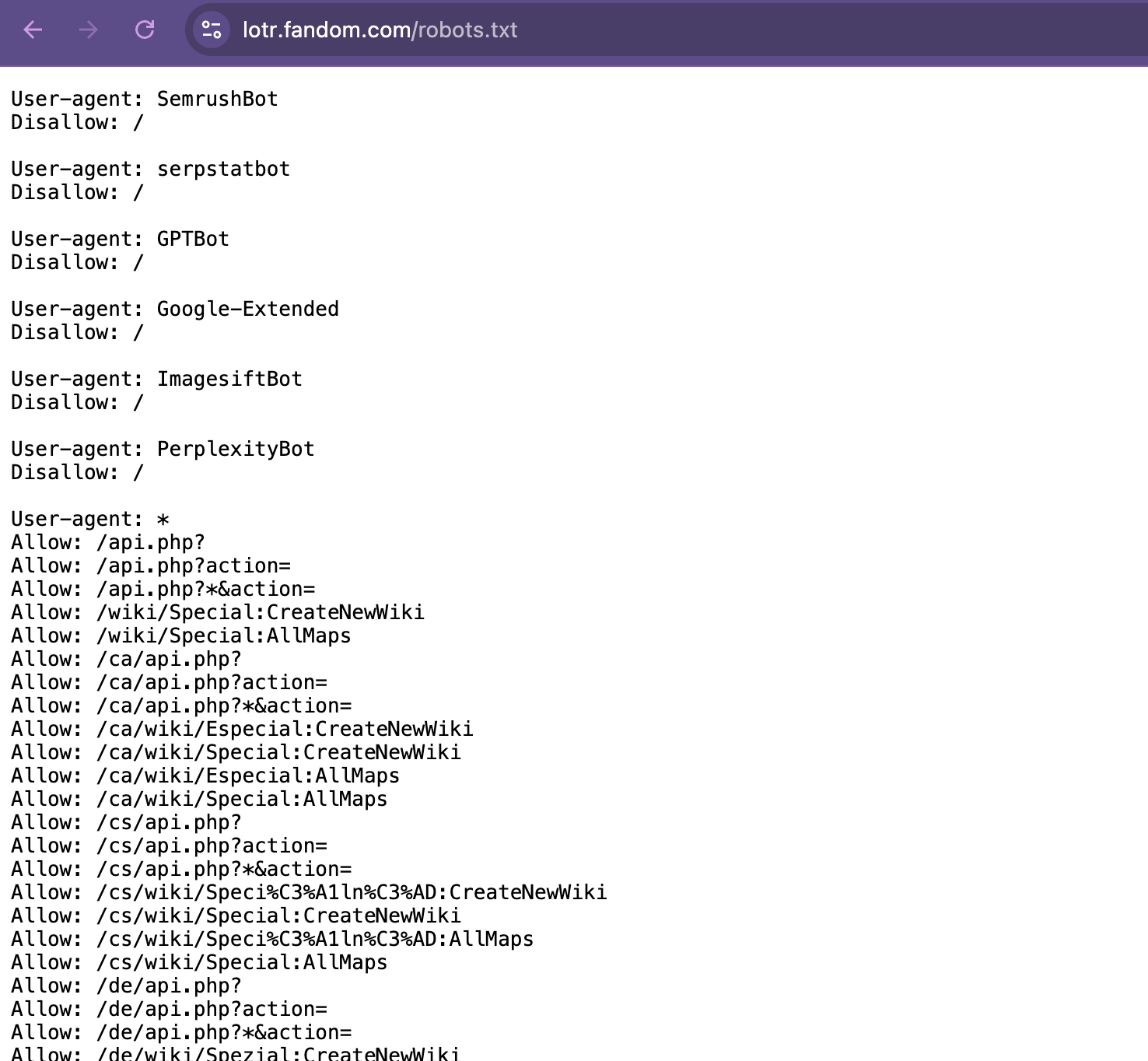
Before scraping any website, you should always check the robots.txt file and the terms of service. The robots.txt file is located at the root of a website and tells you what content can be scraped.
For example: https://lotr.fandom.com/robots.txt
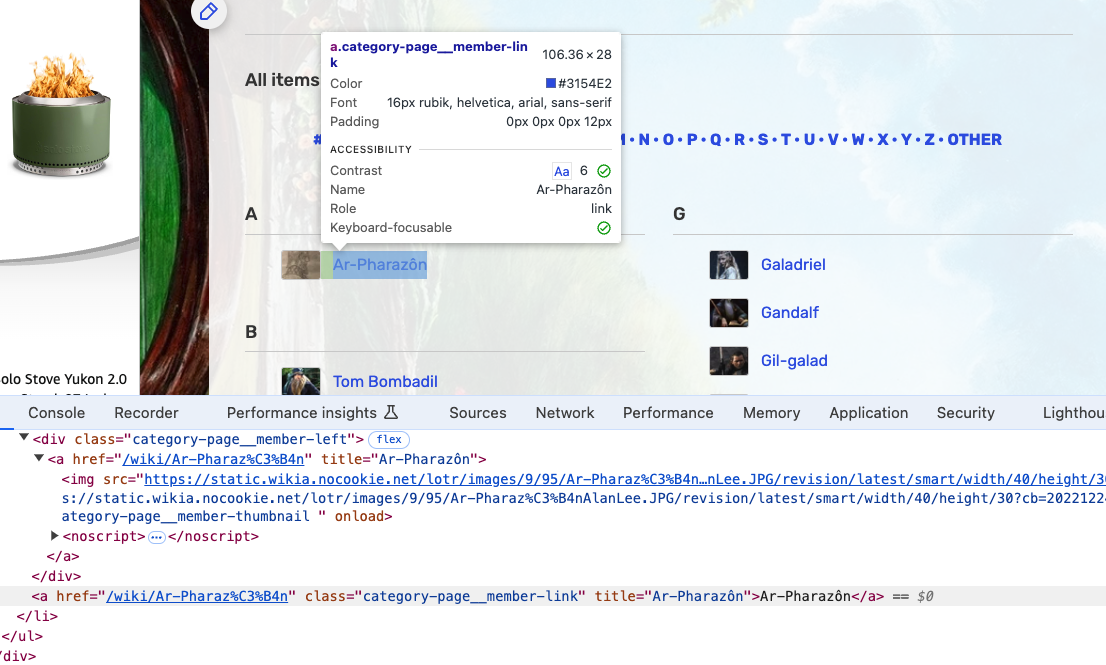
Inspecting Complex HTML
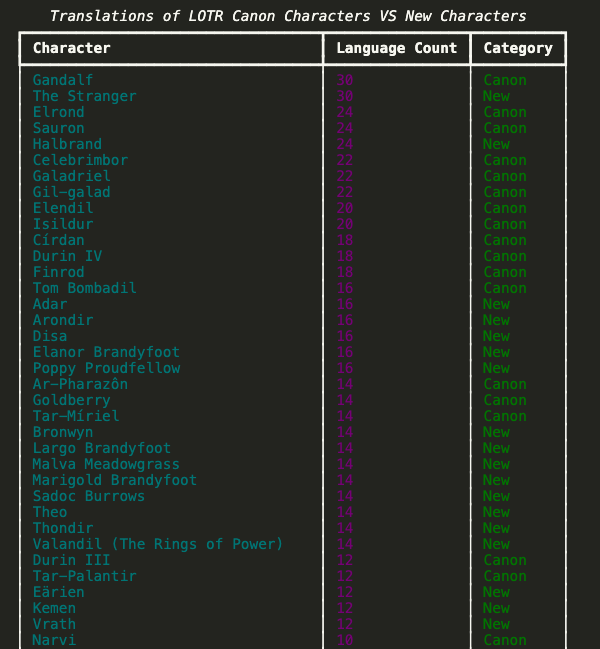
Complex websites have more complex HTML. We need to inspect the page carefully to find the right CSS classes or IDs to target. In this example, each character is in an element with the class category-page__member-link.
Displaying Results with Rich
The Rich library can display our data in a beautiful table:
from rich.console import Console
from rich.table import Table
console = Console()
table = Table(title="LOTR Characters")
table.add_column("Character", style="cyan")
table.add_column("Category", style="magenta")
for character in all_characters:
table.add_row(character['character'], character['category'])
console.print(table)