Semester Long Project 50%
The remainder of your grade will be determined through a semester-long group project. The goal of this project is to expose you to how we create and work with culture as data. As stated above, this project will be completed in groups, and you will be assessed both on your individual contributions and the group’s final submission. The final project is modeled on the Responsible Datasets in Context Project (RDC) https://www.responsible-datasets-in-context.com/, which was created to help students “work with data responsibly.” While we will be using these datasets to practice and learn how to programmatically work with data, they also provide an example of how best to curate and share data about complex cultural phenomena and objects.
As the authors of the project write in the mission statement:
“Data cannot be analyzed responsibly without deep knowledge of its social and historical context, provenance, and limitations. Anyone who works with data—from academic researchers to industry professionals—will know this claim to be true.
But despite its significance, social and historical knowledge and methodologies are one of the most neglected areas in undergraduate computing education. In classes, it is very common for students to use datasets that they find on websites like Kaggle, datasets that are poorly documented and that students thus don’t fully understand. This is a recipe for irresponsible data work and a bad habit that can become a dangerous habit as the stakes get higher.”
While I do not expect you to create as polished or extensive of an output as the datasets available on the RDC Project, you will be working collaboratively to create a first draft of what could eventually be part of this project.
Project Deadlines & Milestones
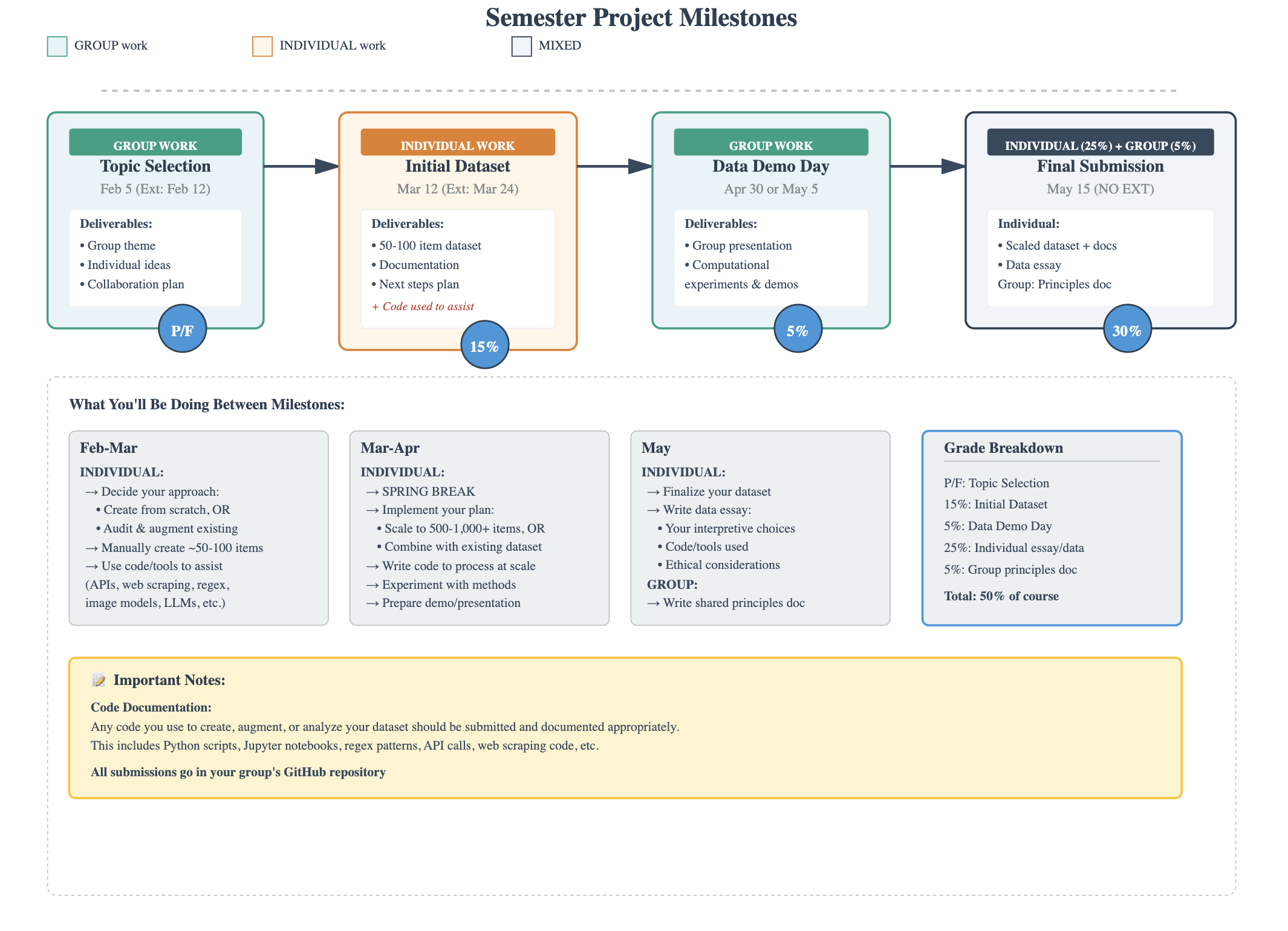
Collective & Individual Topic Selection
DUE FEBRUARY 5, 2026 (Optional Extension to February 12, 2026) PASS/FAIL Grade
In the first two weeks of the course, you will be assigned to a group based on shared interests and complementary skill sets. Your first task is to collaboratively determine the overall thematic focus of your group, as well as brainstorm some potential topics for your individual dataset. You will have time to work on this planning document in class and will submit it as a Markdown file in your group’s GitHub repository.
This planning document should address:
- Group Theme: What is your shared area of interest? What kinds of cultural objects, practices, or phenomena fall within this theme? What’s included and what’s beyond scope?
- Individual Ideas: What specific dataset is each group member considering? How do these relate to the group theme? Why this topic? (These can be preliminary. You’ll develop them further as the semester progresses)
- Collaboration Plan: How will your group communicate and share progress? What’s your GitHub organization strategy?
Format & Submission
- Feel free to use one or multiple Markdown files in the root of your GitHub repo or a planning/ subfolder, depending on what makes sense for your group.
- Use headings, bullet points, links, images, or tables if helpful
- NO WORD COUNT. The goal of this submission is to just help you start to concretize your ideas for the final project and start to figure out how you will handle working collectively on one group repository.
Initial Dataset Submission
DUE MARCH 12, 2026 (Optional Extension to March 24, 2026) 15%
This is your first major deliverable, and it focuses on creating a small, bespoke dataset through close, interpretive work. The goal is to understand what it means to make data carefully—item by item, decision by decision—before you attempt to scale that work computationally. You will create approximately 50-100 data items that reflect deep engagement with a particular cultural object, practice, or phenomenon.
Why small? We start with small-scale, bespoke data creation for a crucial reason: this is where you learn that every dataset embeds interpretive choices. When you manually work through 75 items, deciding what counts, what to capture, how to categorize, you experience the intellectual and ethical labor that gets hidden when you download a dataset or automate collection at scale. It is also an opportunity to get creative and think about what data you wish would exist for your cultural topic of interest.
What about computation? While your dataset is small and reflects close interpretive work, you are required to use computational tools to assist your process. This is not about automation—it is about understanding how computation can augment even bespoke data work. Essentially, we want to break the divide between manual and automated to explore how computation and data can assist across scales.
To address this, your dataset must implement at least one of the following approaches:
- Create Data from Scratch: Today, we are often handed datasets without ever experiencing the messy, interpretive process of creating one ourselves. This approach invites you to explore how complex cultural materials—say, a sculpture or a medieval manuscript—get transformed into structured data. While this may sound straightforward, every step involves interpretive decisions that shape how others can engage with the data downstream.
- For example, if you are interested in the history of children’s literature and working with a lesser-known author whose work has yet to be digitized, you could scan those materials and decide what to capture: Is it just the text? The illustrations? The paratextual material? You might use image models to extract drawings and text, enabling analysis of the author’s evolving style.
- Alternatively, if you might be curious about how students are using AI in their daily lives and could turn to social media platforms like TikTok. While we cannot conduct human-subject research in this course (e.g., no surveys or interviews requiring IRB approval), you could analyze publicly posted videos. For instance, you might annotate TikToks that mention AI to track recurring themes or rhetorical patterns.
- These are just a few possibilities, but whatever your focus, this approach requires you to define a clear methodology, justify your sampling, and carefully document your decisions. You are not just collecting data. You are making data, and that comes with responsibility.
- Audit and Augment Existing Data: Not all responsible data work begins from scratch though. In fact, some of the most important contributions come from uncovering how existing datasets were made, what they omit, and how they might be improved. This approach asks you to critically engage with an existing dataset—especially one that lacks documentation or transparency—and to make its origins, structure, and limitations legible to others.
- For example, you might find a movie dataset on Kaggle that includes scraped reviews and ratings, but provides little information about where the data came from or how it was cleaned. You could trace the dataset back to its source—say, IMDb or Rotten Tomatoes or even historic newspapers—and compare a sample of the original reviews to what appears in the dataset. Were the reviews shortened or misattributed? What patterns of exclusion or distortion emerge? How much has been lost in this process?
- Or you might find a dataset that is widely reused but lacks key metadata or flattens the complexity of the phenomenon it represents, like popular economic benchmark datasets like GDP. Your goal then would be to try and reintroduce that complexity either through supplementing it with missing information, reconciling conflicting sources, or annotating entries to flag inconsistencies or bias. These contributions not only enhance the dataset, but also model what responsible reuse looks like.
- Whatever dataset you choose, this approach requires you to investigate its provenance, reflect on its transformations, and augment it in some meaningful way—whether by correcting errors, adding annotations, or merging it with new material. Just like with data creation, you’ll need a clear methodology, a justification for your interventions, and a well-documented data biography that makes your process transparent.
Format & Submission
Your submission includes three components:
- Initial Dataset (~50-100 items). Your bespoke dataset in a structured format of your choice. You should have a rationale for how you have organized your data.
- Initial Documentation. Your first attempt at documentation that you think best reflects your process, interpretative choices, and explains the dataset. Some questions you might want to address include:
- What cultural materials are you working with and why? What approach did you take (from scratch or auditing)?
- What computational tools did you use to assist your work? How did they help? What were their limitations?
- What decisions did you make about what to include, exclude, or how to categorize? Why? What challenges did you encounter? How did you address them? What patterns, questions, or tensions emerged from working closely with this data?
- Next Steps. After creating this bespoke dataset, after Spring Break, you will work on scaling or expanding your dataset with computation. This plan should outline how you will address the following questions:
- How will you generate more data computationally (Option 1: scale up to 500-1,000+ items using automation)? Or will you combine your bespoke data with an existing large dataset (Option 2: audit, merge, and analyze)? What computational methods will you use? (APIs, web scraping, LLMs, pattern matching, etc.)
- What will change when you scale? What interpretive decisions will you try to automate? What technical challenges do you anticipate?
This plan is your roadmap for understanding how scale transforms data work. You don’t need to implement it yet—but you should be thinking critically about what happens when you move from 75 carefully crafted items to 1,000 algorithmically generated ones.
Your initial dataset should be submitted in your group’s GitHub repository and you should update any collective documentation to help users navigate the files and folders.
Final Project Submission
DUE MAY 15, 2026 NO EXTENSIONS 35%
This is the culmination of your semester-long engagement with culture as data. By this point, you will have created data manually with computational assistance, augmented it at scale, and experimented with computational methods. Now you will submit your complete dataset and write scholarly essays that demonstrate what you have learned about the interpretive, technical, and ethical dimensions of representing culture as data, as well as how you situate your work in broader scholarly data practices.
Your final submission includes both individual and collaborative components, all submitted via your group’s GitHub repository.
Individual Data Essay & Dataset 30%
Culture As Dataset: You will submit your dataset that contains both your bespoke manual work and your computational augmentation at scale. It should be in a structured format, thoughtfully organized, and accompanied by relevant documentation, which is detailed in the next section.
Culture As Documentation: Along with your dataset you will submit both documentation of your dataset but also a final data essay that tells the story of your dataset—how you made it, what it represents, what it reveals, and what it conceals. This essay should demonstrate your intellectual growth over the semester and your ability to critically reflect on the process of working with culture as data. You should pay special attention to explaining how computation played a role in your dataset; how scale shaped the data over the semester; the limitations or qualifications of your dataset; any ethical or privacy considerations; any lessons learned; and finally, how you situate your work in published peer reviewed scholarship.
More details about both parts of this assignment will be discussed over the course of the semester.
If you received a low mark on your Initial Dataset Submission and feel that your final work substantially demonstrates your growth and engagement with the material, you may request that the Initial Dataset grade be dropped and its weight (15%) folded into this component. To request this, contact the instructors before the final submission deadline with a brief explanation of how your final dataset and essay address the shortcomings of your earlier submission. This is not automatic option, it requires a deliberate case for your development over the semester.
Collective Principles & Documentation 5%
Your group will collaboratively write a document with you group that synthesizes what you collectively learned about working with your particular type of cultural data. This is NOT a repeat of individual data essays—it’s methodological guidance and collective wisdom for future researchers.
Think of this as: Writing the documentation you wish had existed when you started this project. What should someone know before they attempt to represent music as data? Or social media? Or gaming culture? What principles emerged from your group’s diverse approaches to similar materials? At its core, this document should include a set of principles for working with your cultural topic as data. The document should also attempt to note how each member contributed to its format, and like all work it will be submitted in your group’s collective GitHub repository.