Getting Cultural Data From APIs
So far in class we have briefly mentioned APIs (for example, the Spotify API), but haven’t yet discussed what they are or how to use them. This week we will start to work through the basics of using APIs to get data from the web.
What is an API?
API stands for Application Programming Interface, but what does that mean exactly?
While according to Wikipedia,
An application programming interface is a connection between computers or between computer programs. It is a type of software interface, offering a service to other pieces of software. A document or standard that describes how to build or use such a connection or interface is called an API specification.
But while that is technically correct, it probably leaves you with more questions than answers.
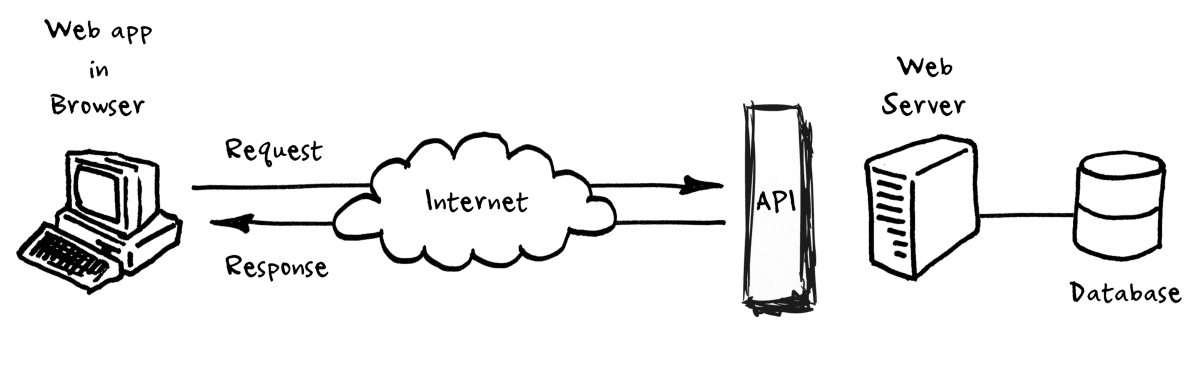
In this figure, you’ll notice that we have a web browser that is using the “internet cloud” to make requests and get responses from an API that is connected to a web server and a database. This might seem complex, but we’ve seen a similar relationship when we talked about how the web works. We learned previously about how web browsers use HTTP to make requests and get responses from web servers, this is essentially the same concept. APIs are just a way to get data from a server, similar to how we get web pages from a server, but instead of storing the data in a webpage (aka an HTML document), the data is stored in a database. For example, when you use a weather app, or really any app on your phone, that app is using an API to get the weather data from a server.
Databases might also sound intimidating, but they are just a way to store data, similar to .csv or .json files. The difference is that databases are designed to store large amounts of data and to allow that data to be accessed and manipulated quickly, usually using something called SQL (Structured Query Language), which is a programming language that allows you to interact with databases.
Rather than going to a URL in your browser, an API lets us send a similar request to a server. To help us understand APIs, let’s explore a bit of their origins and development.
While HTTP and HTML were became popular in the late 1980s and 1990s, APIs only became popular in the early 2000s. Kin Lane, the API Evangelist, has a blog post titled “The History of APIs” https://web.archive.org/web/20190722130022/https://history.apievangelist.com/, which explores this history.1
According to Lane, one of the first APIs was developed by Salesforce in 2000, which allowed developers to access data from their databases and to build applications for customer relationship management. This initial API provided access to XML data, which is a type of markup language similar to HTML (remember TEI?). This was followed by eBay, which also developed an API in 2000.

While a lot of the infrastructure and standards for APIs were developed during the same period as the earlier web history, what really made APIs start to take off in the mid-2000s was the emergence of Web 2.0.

Web 2.0 was a term coined by Tim O’Reilly in 2004 to describe a new era of the web that was more interactive and user-driven. This era saw the rise of social media platforms like Facebook, YouTube, and Twitter, which allowed users to create and share content online. These platforms started to have massive databases of user-generated content, and so to access this data, they needed to develop APIs.
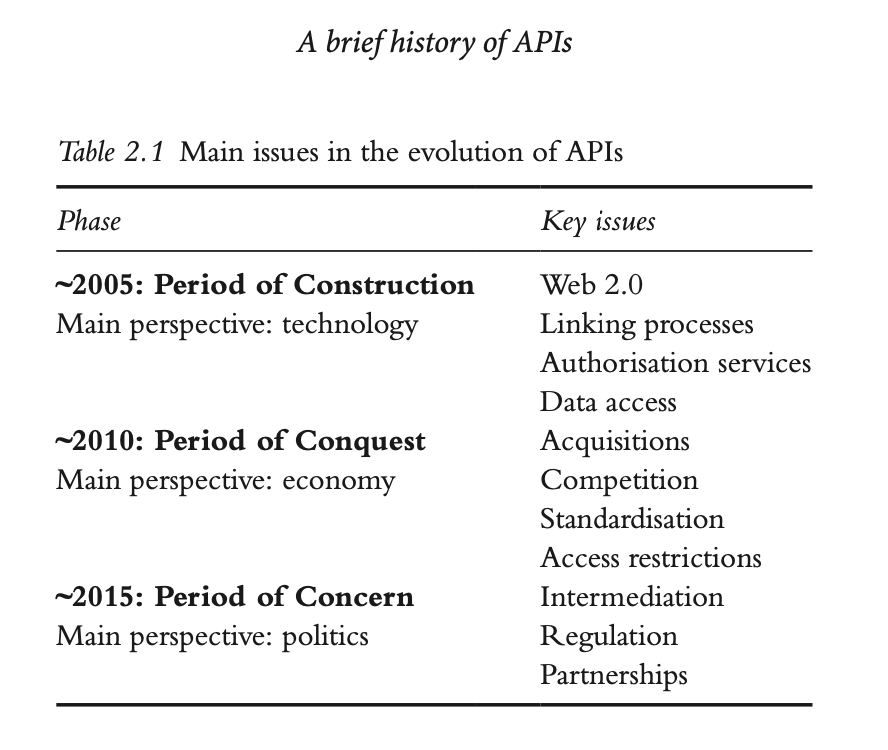
The figure above comes from the chapter “A Brief History of APIs” by Jakob Jünger. Jünger argues that while the early 2000s were important for popularizing the idea of “mashups” (combining data from multiple sources), the mid-2000s saw the rise of social media APIs. Facebook, YouTube, and Twitter all introduced APIs that allowed developers to build applications that integrated social media data. For example, YouTube’s API allowed developers to upload videos and access analytics data, while Facebook’s API allowed developers to build applications that integrated with the Facebook platform, specifically their Social Graph API, which allowed developers to access data about users and their connections.2
The growth in these platforms then led to the rise of third-party applications that used these APIs. For example, you might have heard of TweetDeck, which is/was an incredibly popular Twitter client that allowed users to manage multiple Twitter accounts and to schedule tweets and was bought by Twitter in 2011. Similarly, Google introduced the OpenSocial initiative in 2007 to try and standardize API interactions, but it largely failed, with most platforms retaining unique APIs. Facebook and Twitter in particular prioritized control over data access and usage through increasingly strict terms of service.
While TweetD TweetDeck was built using the Twitter API, which allowed developers to access data about tweets, users, and trends. This era of APIs was characterized by a proliferation of third-party applications and platforms, as well as a push for standardization. Google and others attempted to standardize API interactions with initiatives like OpenSocial, but most platforms retained unique APIs, with Facebook and Twitter prioritizing control over data access and usage through increasingly strict terms of service. Part of this focus on control was due to the rise of data privacy concerns, especially after events like the revelations of the Facebook–Cambridge Analytica data scandal in 2018. For those unfamiliar, this scandal was when it was revealed through a New York Times and The Guardian investigation that the political consulting firm Cambridge Analytica had harvested data from millions of Facebook users without their consent and used it to target political ads during the 2016 US presidential election. In the aftermath of this scandal, many of these platforms have restricted access to their APIs, leading computational social scientist, Deen Freenlon, to term this as the “post-API age.”3
Understanding this history is helpful because it gives us a sense of the many users of APIs, as summarized in the table below:
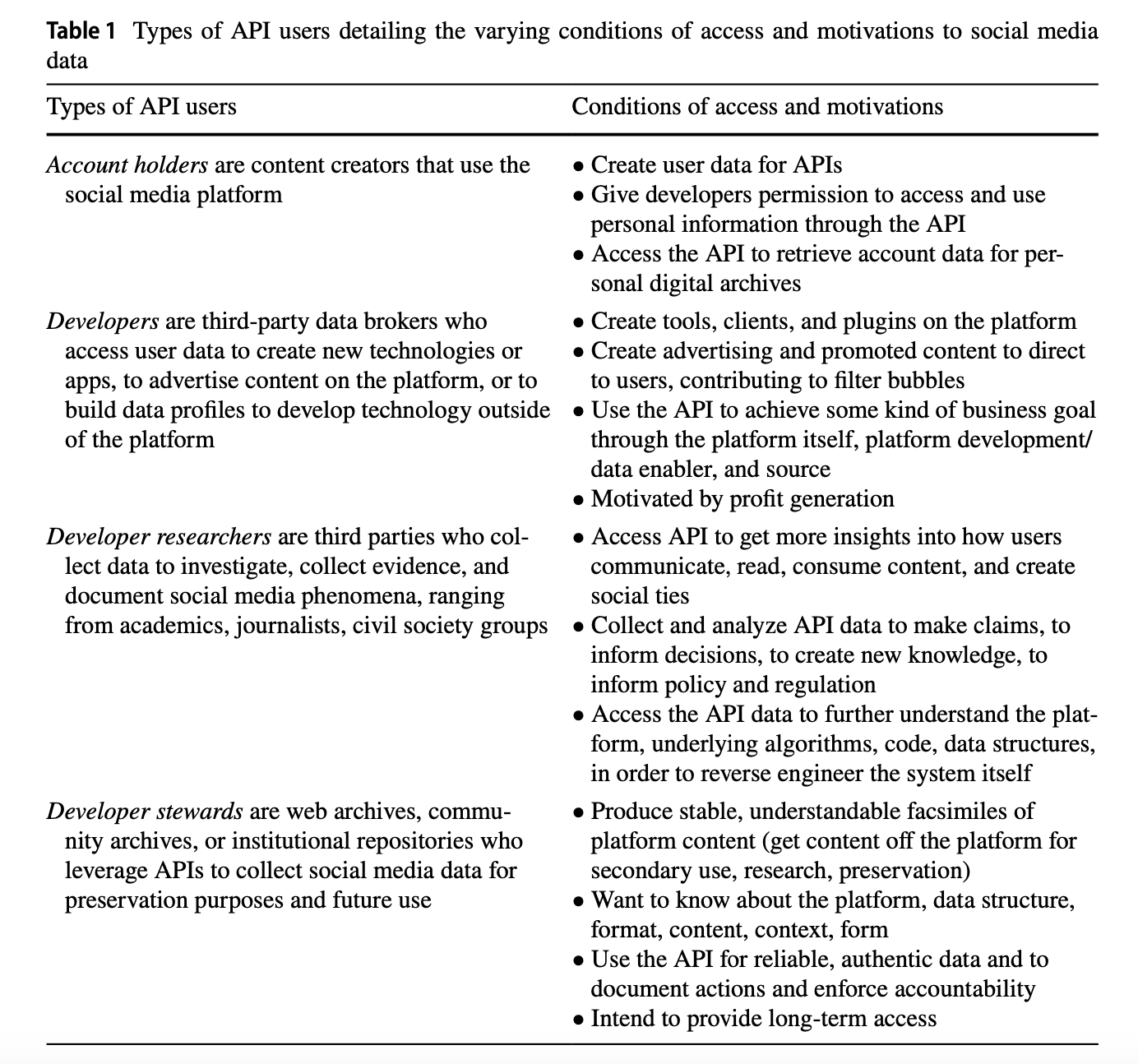
This table comes from Amelia Acker and Adam Kreisberg’s article “Social Media Data Archives in an API-Driven World” which explores how APIs are limiting access to social media data and the implications of this for archiving and research; a topic we’ve discussed in class.4 You’ll notice in this table they identify a number of different users of APIs, including individual account holders on a platform (so if you’ve ever tried to export your social media data for example), developers who build applications that use APIs, develop researchers which are researchers who use APIs to access data for their research and especially for those who study these platforms, and lastly, developer stewards who are often archivists and preservation specialists who use APIs to collect and preserve data. While these groupings are not definitive or exhaustive, they give us a sense of the many different users of APIs and the many different ways APIs are used. However, it is critical to understand that very few APIs are designed to be used by this many different groups of users, and that instead the majority of APIs are designed to be used by a single group of users, often developers building applications since that is the most profitable use of APIs.
Working with APIs
Now that we have a sense of what an API is and how they have developed, let’s start to work with them. We are going to be building from our web scraping lesson, using the requests library and once again working with Lord of the Rings data, but this time we are going to use The One API https://the-one-api.dev/. For those unfamiliar, the one in the name is a reference to the Lord of the Rings series, where the One Ring is the most powerful of the Rings of Power and is the central plot device of the series.
According to the documentation, “The One API to rule them all is a non-commercial, open-source project” and provides access to data from the Lord of the Rings books and movies, including characters, quotes, and books.
If we go to the about page https://the-one-api.dev/about, we can learn that the project was created in 2019 by Ulrike Exner and Mateusz Kikmunter, who are both developers. We can also visit the GitHub repository for the project https://github.com/gitfrosh/lotr-api/graphs/contributors to see the history of the project.
So let’s try this out!
Making an API Request
In your is310-coding-assingments, create a new folder called api-getting-data and then create a new script called first_api_script.py. In this script, import the requests library and then create a variable called url that is the base url for the LOTR API.
import requests
url = 'https://the-one-api.dev/v2/book'
If you get an error, running this code telling you that requests is not installed. Please remember to activate your Python virtual environment!
Now how could we use this URL to get data from the API? We could use the requests.get method we used in the web scraping lesson. Let’s try that out.
response = requests.get(url)
How could we see that this request worked? We can print the status code of the response.
print(response.status_code)
Hopefully we are all seeing 200 responses, but if you are seeing a 404 or 403 response, you might need to authenticate with the API. We will discuss this more in the next section, but for now, let’s try to print out the response.
In our web scraping lesson, we used the .text method to print out the response, but for APIs, we often use the .json() method. Let’s try that out.
print(response.json())
You should see something like the following:
{
'docs':
[
{
'_id': '5cf5805fb53e011a64671582',
'name': 'The Fellowship Of The Ring'
},
{
'_id': '5cf58077b53e011a64671583',
'name': 'The Two Towers'
},
{
'_id': '5cf58080b53e011a64671584',
'name': 'The Return Of The King'
}
],
'total': 3,
'limit': 1000,
'offset': 0,
'page': 1,
'pages': 1
}
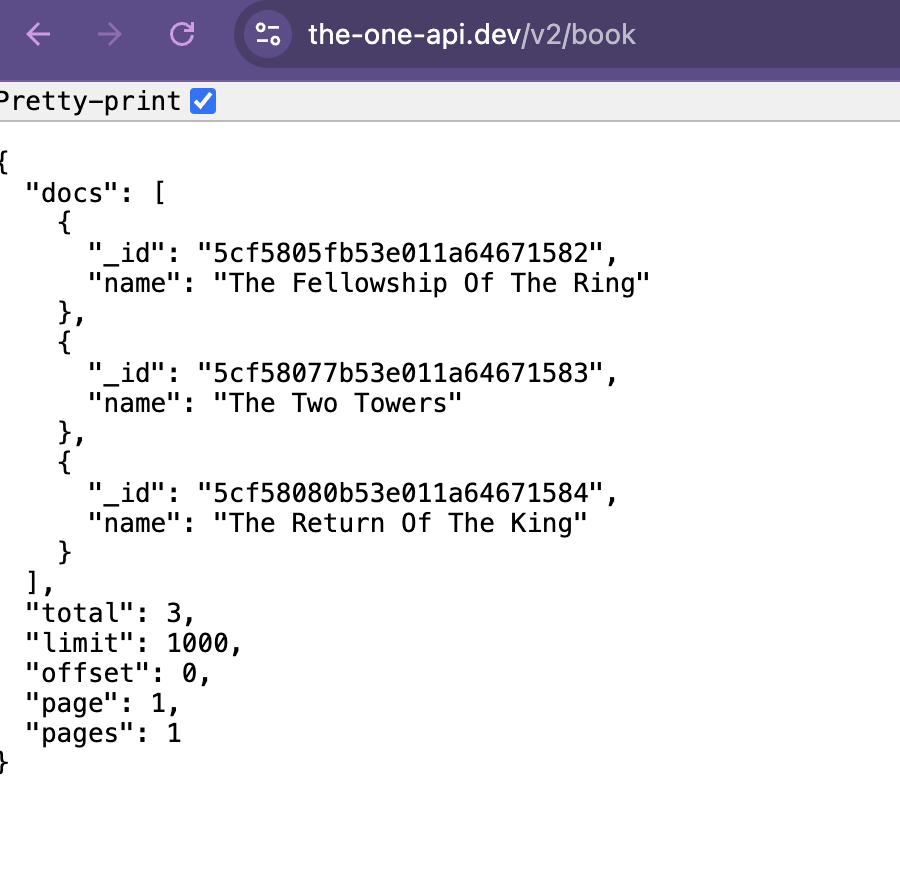
This is the data that The One API returned to us. It’s in a format called JSON, which stands for JavaScript Object Notation and was originally designed to allow websites to pass data back and forth between the browser and the server. But it’s become a really popular generic format for all sorts of things and all sorts of languages. You’ll notice that JSON looks very similar to a Python dictionary, and in fact, it’s a way to store data that is similar to a Python dictionary.
Based on this data, we can see that The One API has returned data about the three books in the Lord of the Rings series. Each book has an _id and a name. The books themselves are returned in a list for the key docs, and then there are some other keys that provide information about the data that was returned, including total, limit, offset, page, and pages. Total tells us how many items were returned, limit tells us how many items could be returned per page, offset tells us where in the data we are (similar to indexing), page tells us what page we are on, and pages tells us how many pages of data there are.
While this is a pretty minimal amount of data, it does give us a sense of how APIs work. Just as if we were going to a web browser, we can make requests to an API and get data back. This data will be structured in some way and we can use that structure to understand the data and to work with it. It is important to note that there is no one way that APIs are structured, and each API will have its own structure and its own way of working. This is why it’s important to read the documentation for an API before you start working with it.
Authentication & Endpoints
So far we have just been able to send a request to The One API and get data back, but what if we wanted to get more specific data? For example, what if we wanted to get data about a specific character or quote from the Lord of the Rings series? To do this, we need to use something called an endpoint.
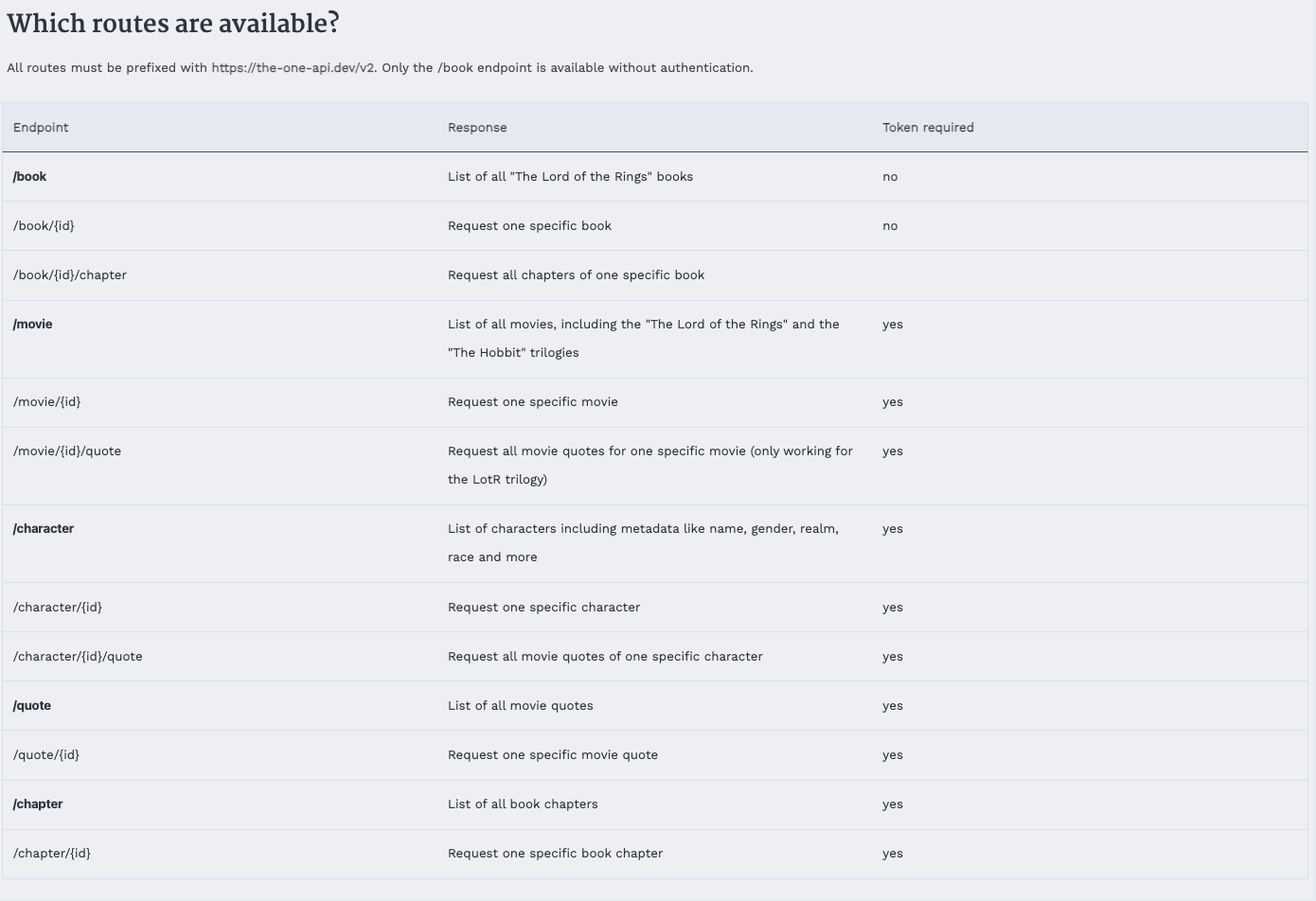
If we go to The One API documentation https://the-one-api.dev/documentation#4, we see the following table that outlines what endpoints exist.
An endpoint might sound like a very technical term, but it is essentially just a specific URL that is used to access a specific piece of data from an API. For example, if we wanted to get data about a specific character, we would use the /character endpoint. If we wanted to get data about a specific quote, we would use the /quote endpoint.
We can even try out that initial book endpoint in the browser which should give us the following:
However, if we try to get characters or quotes in the browser, we will see the following:

Indeed, if we update our python code we can see the exact same thing.
url = 'https://the-one-api.dev/v2/character'
response = requests.get(url)
print(response.status_code)
This should return a 401 status code, which means that we are not authorized to access this data. This is because the LOTR API requires us to authenticate before we can access data about characters or quotes. This is a common feature of APIs, as it allows the API to track who is accessing their data and to limit access to certain users.
Authentication can sound intimidating but you actually do it all the time already. For example, when you login to your email, you are authenticating with a server to access your email. When you login to DUO, you are authenticating with a server to access your account. When you login to social media, you are authenticating with a server to access your account. The difference is that when you use a web browser, this is all handled automatically for you, but when you use an API, you have to do this explicitly.

If we return to The One API documentation https://the-one-api.dev/documentation#3, we can see that we need to sign up for an account to use the API at this link https://the-one-api.dev/sign-up.
Once you have signed up and logged in, you should see the above page for your account, which will include your API key. This key is unique to you and is used to identify you when you make requests to the API. It’s like a password, so you should keep it secret and not share it with anyone.
You should copy the key into your first_api_script.py and then try to get data about characters or quotes.
api_key = "API KEY HERE"
url = 'https://the-one-api.dev/v2/character'
authorization_headers = {
'Authorization: Bearer ' + api_key
}
You’ll notice that we are using a new variable called authorization_headers that is a dictionary with a key of 'Authorization' and a value of 'Bearer ' + api_key. This is how we pass our key to The One API so that it knows who we are and that we are allowed to use their API.
Now let’s update our requests.get method to include these headers.
response = requests.get(url, headers=authorization_headers)
print(response.status_code)
Now we should see a 200 status code, which means that we are authorized to access this data. Before we explore this new data, we need to first understand how to store our API keys securely.
Currently, we just have our api key in a string in a variable, which is easy to use but it’s not the most secure. For example, if you pushed this up to GitHub, then everyone would be able to see and use your API key. You’ll notice that The One API says that you should limit your requests “to 100 requests every 10 minutes”. However, if you shared your key, someone could easily use it and you would be locked out of the API. Even worse, if they did something illegal with your key, you could be held responsible. So rule of thumb is don’t share your API key!
Storing API Keys
There are a number of ways to more securely store your API keys.
One option is just copying our API keys to a text file and save them there (especially because they are rarely something you can memorize), but there’s also more programmatic ways to do this.
Another option is that you could store your API keys as an environment variable. Environment variables are a way to store data that is accessible to all programs running on your computer.
To create an environment variable, you open your terminal and type the following, replacing api_key with your API key.
For Macs/WSL:
export THE_ONE_API_KEY="YOUR_API_KEY_HERE"
For Windows/PowerShell:
setx THE_ONE_API_KEY "YOUR_API_KEY_HERE"
Now you can access these environment variables in your Python script by using the os library.
import os
the_one_api_key = os.environ['THE_ONE_API_KEY']
print(the_one_api_key)
However, these will only be available in the terminal you created them in, so you would have to create them every time you open a new terminal. If you want to make them available in every terminal, you can add them to your .bashrc or .zshrc file on Macs/WSL or your profile.ps1 file on Windows.
This is a bit more work though, and one easier option is to use a Python library for storing API keys, called apikey https://github.com/ulf1/apikey.
In your terminal, type pip install "apikey>=0.2.4 to install the library. Then import it into your script and write:
import apikey
apikey.save("THE_ONE_API_KEY", "YOUR_API_KEY_HERE")
the_one_api_key = apikey.load("THE_ONE_API_KEY")
While you can use any of these options, I would recommend using the apikey library, as it’s the most secure and the easiest to use. If you continue with programming, you will likely end up using the .zshrc or .bashrc method, but for now, the apikey library is the best option.
Making API Requests
Now that we have our api key stored securely, let’s try to get data about characters from The One API. We can do this by updating our url variable to include the /character endpoint.
the_one_api_key = apikey.load("THE_ONE_API_KEY")
authorization_headers = {
'Authorization': 'Bearer ' + the_one_api_key
}
url = 'https://the-one-api.dev/v2/character'
response = requests.get(url, headers=authorization_headers)
if response.status_code == 200:
print(response.json())
else:
print(response.status_code)
This should show a much larger amount of data, including information about all the characters from the Lord of the Rings series in this database. You’ll notice that the data is structured in a similar way to the data about books, with a list of characters and some other information about the data that was returned.
{'docs': [{'_id': '5cd99d4bde30eff6ebccfbbe',
'name': 'Adanel',
'wikiUrl': 'http://lotr.wikia.com//wiki/Adanel',
'race': 'Human',
'birth': None,
'gender': 'Female',
'death': None,
'hair': None,
'height': None,
'realm': None,
'spouse': 'Belemir'},
{'_id': '5cd99d4bde30eff6ebccfbbf',
'name': 'Adrahil I',
'wikiUrl': 'http://lotr.wikia.com//wiki/Adrahil_I',
'race': 'Human',
'birth': 'Before ,TA 1944',
'gender': 'Male',
'death': 'Late ,Third Age',
'hair': None,
'height': None,
'realm': None,
'spouse': None},
{'_id': '5cd99d4bde30eff6ebccfbc0',
'name': 'Adrahil II',
'wikiUrl': 'http://lotr.wikia.com//wiki/Adrahil_II',
...
'total': 933,
'limit': 1000,
'offset': 0,
'page': 1,
'pages': 1}
Since the api response is in json format, we can work with it similar to working with a dictionary. For example, we can see all the keys in the response by using the .keys() method.
response.json().keys()
This should show the following:
dict_keys(['docs', 'total', 'limit', 'offset', 'page', 'pages'])
We can access the total key to see how many characters are in the database.
response.json()['total']
This should return 933, which means that there are 933 characters in the database. We can also loop through the docs key to see each character.
for character in response.json()['docs']:
print(character)
This should show a list of dictionaries, each of which contains information about a character from the Lord of the Rings series. You’ll notice that each character has an _id, a name, a wikiUrl, a race, a birth, a gender, a death, a hair, a height, a realm, and a spouse.
So if we only wanted to see the data about a certain character, like Galadriel, we could loop through the characters and print out the data for Galadriel.
for character in response.json()['docs']:
if character['name'] == 'Galadriel':
print(character)
Which would return the following data:
{'_id': '5cd99d4bde30eff6ebccfd06', 'name': 'Galadriel', 'wikiUrl': 'http://lotr.wikia.com//wiki/Galadriel', 'race': 'Elf', 'birth': 'YT 1362', 'gender': 'Female', 'death': 'Still alive: Departed over the sea on ,September 29 ,3021', 'hair': 'Golden', 'height': 'Tall', 'realm': 'Eregion,Lothlórien,Caras Galadhon', 'spouse': 'Celeborn'}
While we can do this using Python, we could also change our URL to only get data about Galadriel. We can do this by adding a query parameter to our URL.
url = 'https://the-one-api.dev/v2/character?name=Galadriel'
response = requests.get(url, headers=authorization_headers)
print(response.json())
Query parameters are a way to pass data to an API to get specific data back. In this case, we are passing the query parameter name=Galadriel to The One API to get data about the character Galadriel. You’ll notice that the URL has a ? at the end of it, followed by the query parameter name=Galadriel. Returning to the API’s documentation https://the-one-api.dev/documentation#5, we can see that we can use query parameters for sorting, filtering, and pagination data from The One API.

As you can see in the figure above, you can also add multiple query parameters by separating them with an &. For example, if we wanted to get all other elves besides Galadriel, we could use the does not match query parameter name!=Galadriel and chain that with the race query parameter race=Elf.
url = 'https://the-one-api.dev/v2/character?name!=Galadriel&race=Elf'
response = requests.get(url, headers=authorization_headers)
print(f"Total number of elves besides Galadriel: {response.json()['total']}")
Finally, we can also use the id in each data returned from the API to get more specific data. For example, if we wanted to get data about all the movie quotes of Galadriel, we could first get the id of Galadriel and then use that id to get data about her quotes.
url = 'https://the-one-api.dev/v2/character?name=Galadriel'
response = requests.get(url, headers=authorization_headers)
galadriel_id = response.json()['docs'][0]['_id']
quote_url = f'https://the-one-api.dev/v2/character/{galadriel_id}/quote'
response = requests.get(quote_url, headers=authorization_headers)
print(response.json())
Finally, let’s use the time library in Python so that we don’t exceed the 100 requests every 10 minutes limit.
import time
url = 'https://the-one-api.dev/v2/character?name=Galadriel'
response = requests.get(url, headers=authorization_headers)
galadriel_id = response.json()['docs'][0]['_id']
quote_url = f'https://the-one-api.dev/v2/character/{galadriel_id}/quote'
response = requests.get(quote_url, headers=authorization_headers)
print(response.json())
time.sleep(10)
Understanding how to use query parameters and how to use the id of data returned from an API is critical to working with APIs, as it allows you to get specific data from an API. This is especially important when working with large datasets, as it allows you to filter and sort data to get the data you need. Remember collecting all the data is not always the best option, and can actually lead to more work depending on your research question.
Python API Wrappers
So far we have been using the requests library to make our API calls, which is usually how you should work with APIs. However, occasionally, developers will create Python libraries to work with APIs, which can make working with APIs easier. These libraries are called API wrappers, and they are essentially Python libraries that provide a set of functions to work with an API.
You can imagine if instead having to write a requests.get method every time you wanted to get a character and their number of quotes from The One API, we could instead write a Python Class that would make the request and store the data for us. This is what an API wrapper does, it abstracts the process of making requests to an API and allows you to work with the data more easily.
Indeed, a developer named Nathanial Hapeman has created one for The One API, which you can see here https://pypi.org/project/nrh-lotr/0.0.3/. If you want to try out this library, all you have to do is type pip install nrh-lotr==0.0.3 in your terminal.
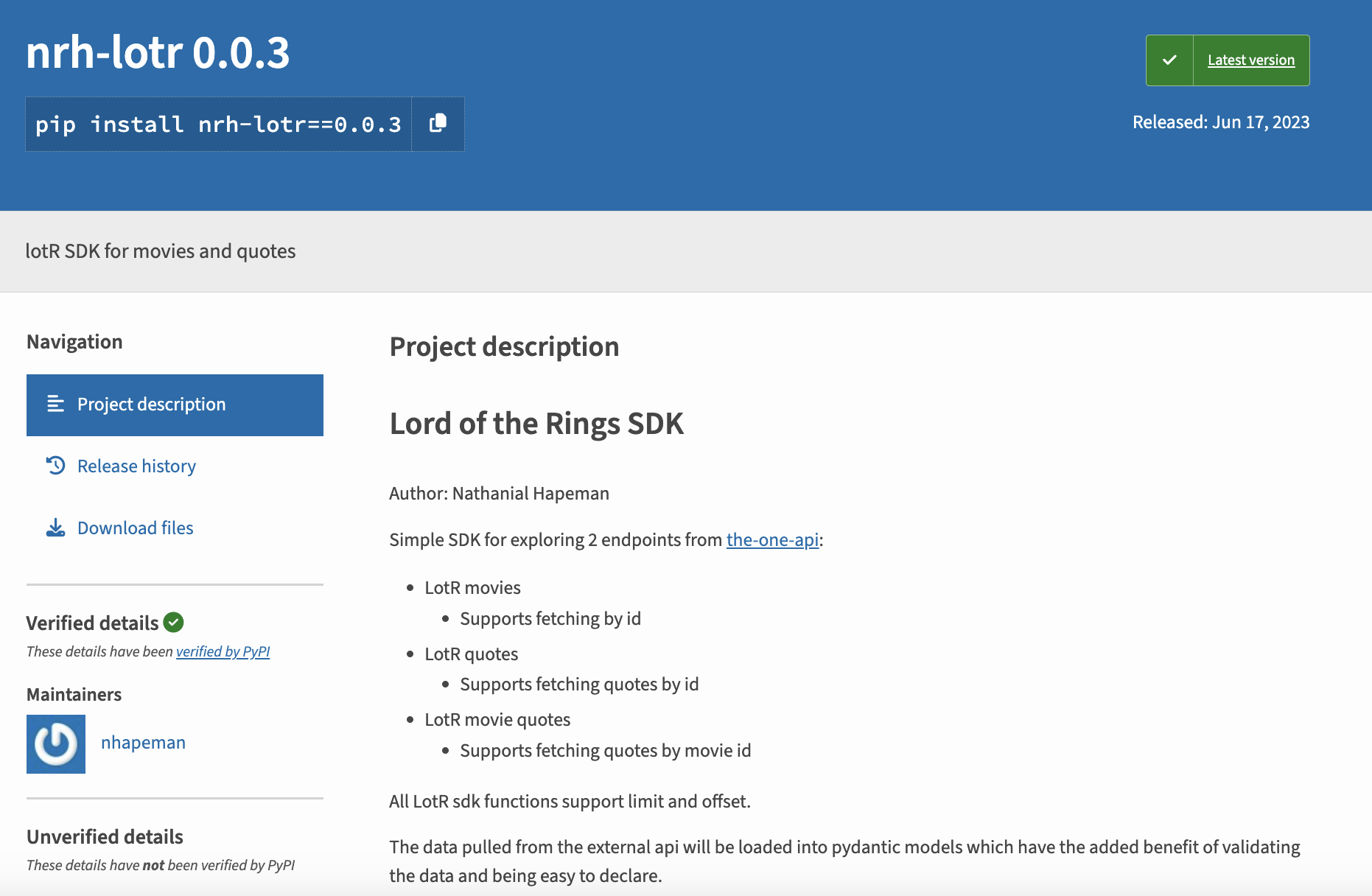
If you scroll down to Usage section, you can see how the developer has created a class called LOTR that takes your api key and then makes requests for you.
# First grab an api key from: https://the-one-api.dev/documentation#3
# Then put it in an env var like: `export API_KEY=SOME_API_KEY`
# Or insert it directly into the LOTR class as depicted below
from lotr import LOTR, Movie, Quote
# Movie basics.
lotr = LOTR("YOUR_API_KEY")
# lotr = LOTR() # if using env var
movies = lotr.movies(limit=5)
We can also see how the library is organized if we inspect it after installing it:
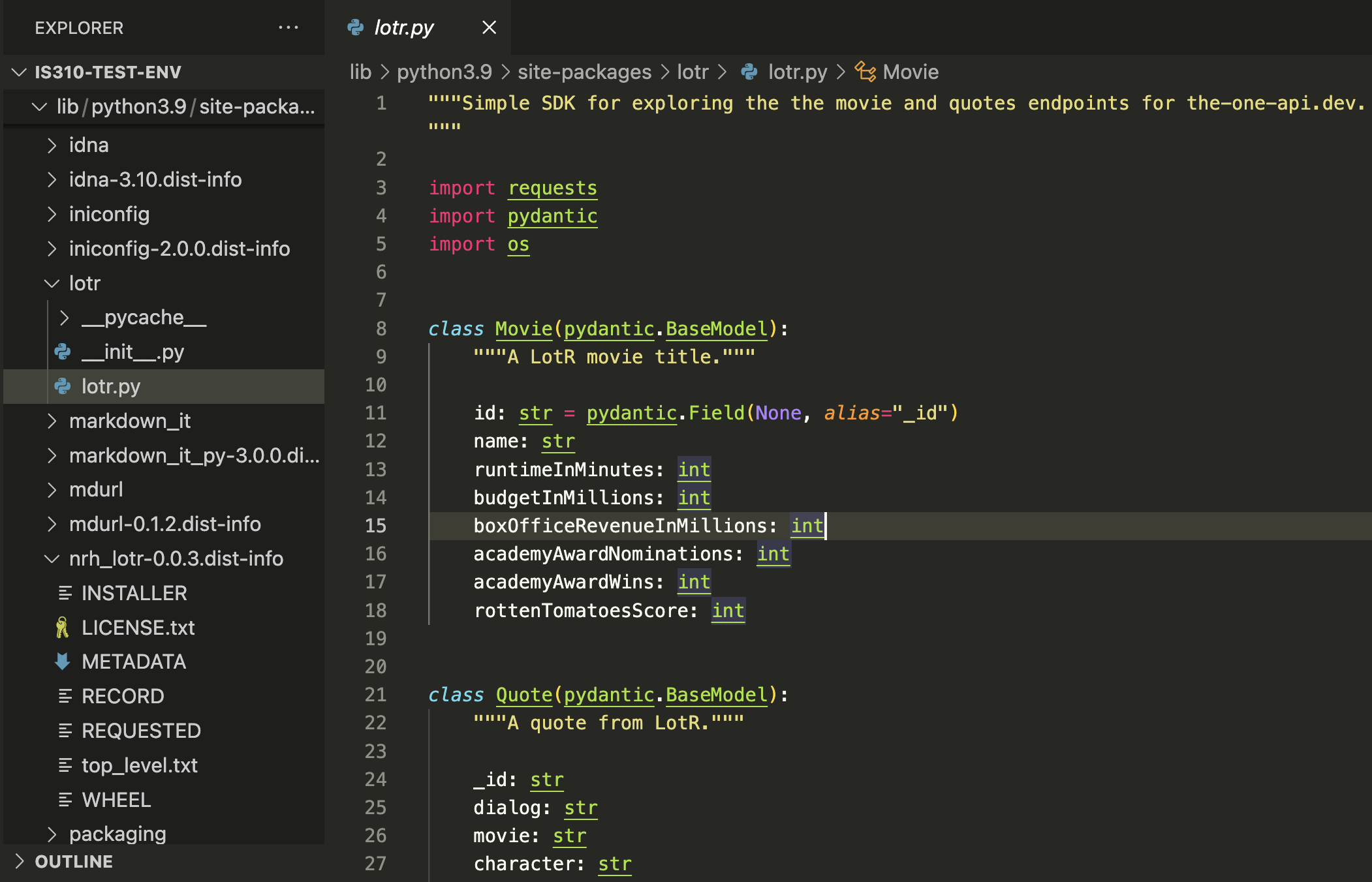
And you can see how’s it making requests to the API by looking at the source code.
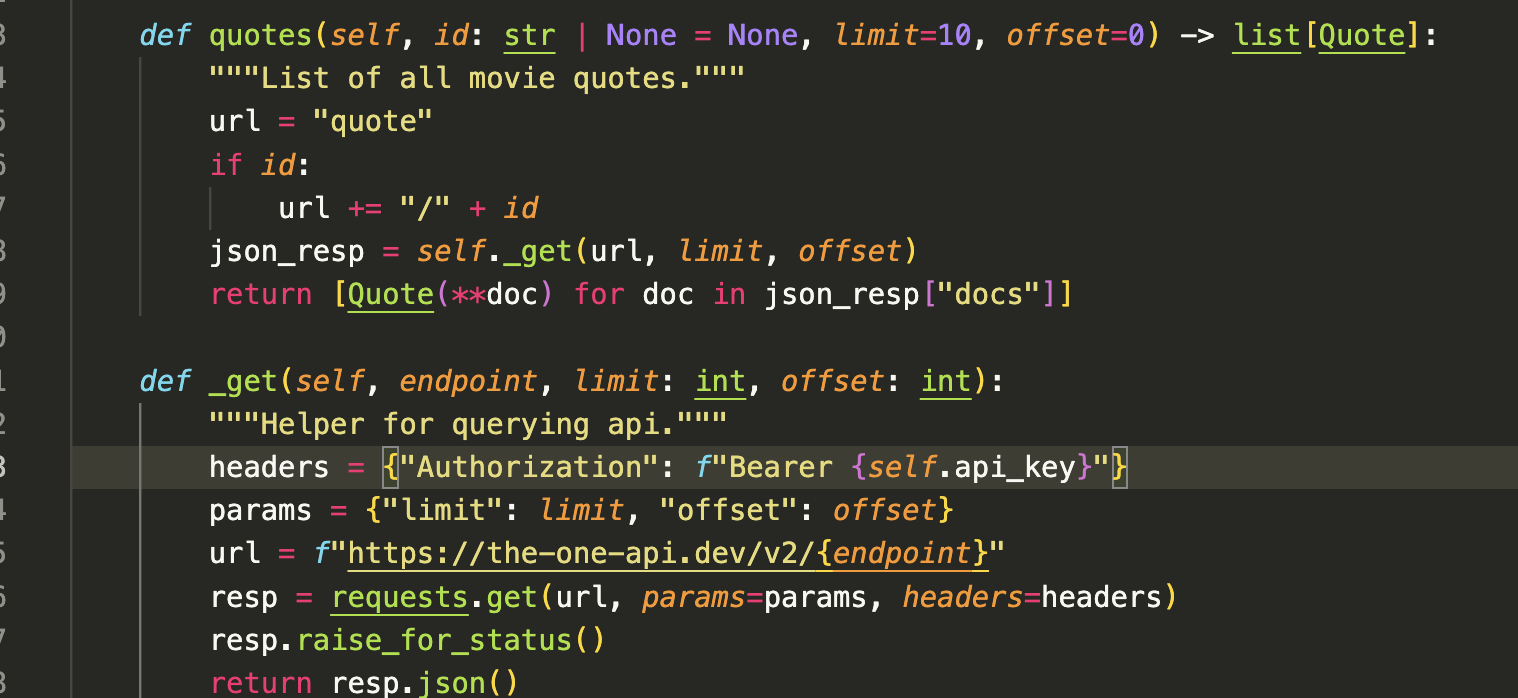
However, if you scroll down further in the documentation, you’ll notice that this library only makes requests for the following endpoints:
/movie
/movie/{id}
/movie/{id}/{quote}
/quote
/quote/{id}
Such limited functionality means that we couldn’t use this library to get data about characters or books, which is a major limitation. These types of limitations are common when working with API wrappers, as they are often created by developers who are not affiliated with the API itself and who may not have the time or resources to create a full-featured library. However, they can be a good way to get started with an API, especially if you are new to working with APIs.
Europeana API & pyeuropeana
Rather than use this library, we’re going to try one that has been designed for the Europeana digital library https://www.europeana.eu/en.
This library was first proposed in 2005 by six European heads of state who signed a letter asking the EU to support the development of a European Digital Library and it was initially released in 2008.5 It provides access to millions of digitized items from European museums, libraries, archives, and galleries, and is a great resource for researchers, students, and the general public. The library has undergone a transformation since its initial release, with the first few years focusing on encouraging heritage institutions to provide their digital material to the platform. The newer version, released in 2016, has more of a focus on encouraging reuse in different ways and curating the collection through exhibitions and collections.
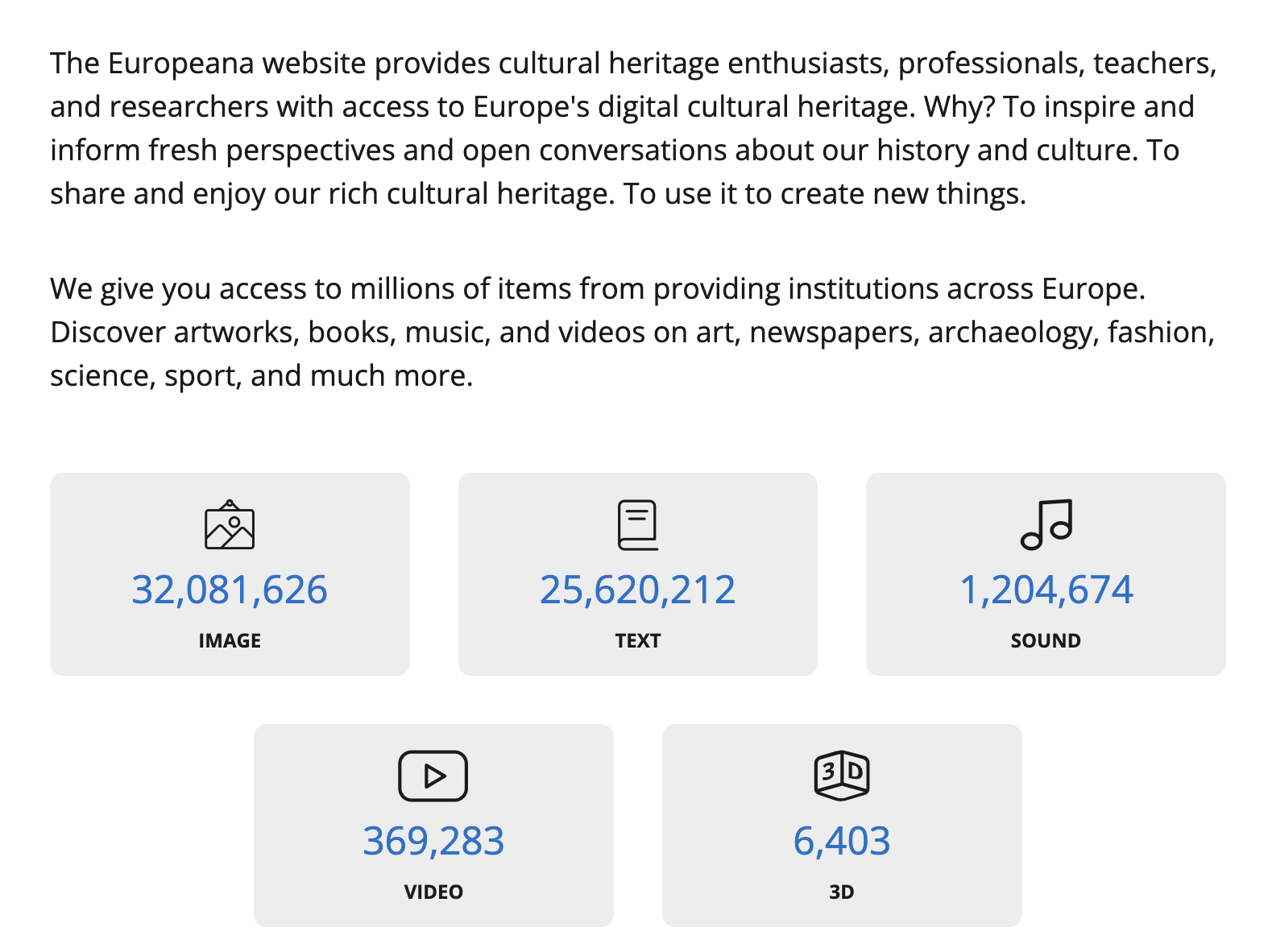
Given the scale and funding for Europeana, there are number of APIs that have been developed for accessing data from the collections. For examples, James Morley has created a Europeana Colour Explorer https://culturepics.org/colour/#/ that uses the Europeana API to explore the colors of items in the collection.
If we click on one of the images, it takes us to the Europeana website where we can see more information about the item. For example, I selected this item https://www.europeana.eu/en/item/1190/INP_postcards_6415?utm_source=api&utm_medium=api&utm_campaign=bkV8GDrrp, which is a postcard from 1852 created by a Romanian artist Gheorghe Tattarescu.

If we scroll down, we can see that the item is part of the National Heritage Institute in Bucharest, Romania and that it is licensed under a Creative Commons Attribution-ShareAlike license. This means that we can use the item for free as long as we provide attribution to the creator and share any derivative works under the same license. We can also start to see some of the metadata available for the item, including the title, creator, date, and rights.
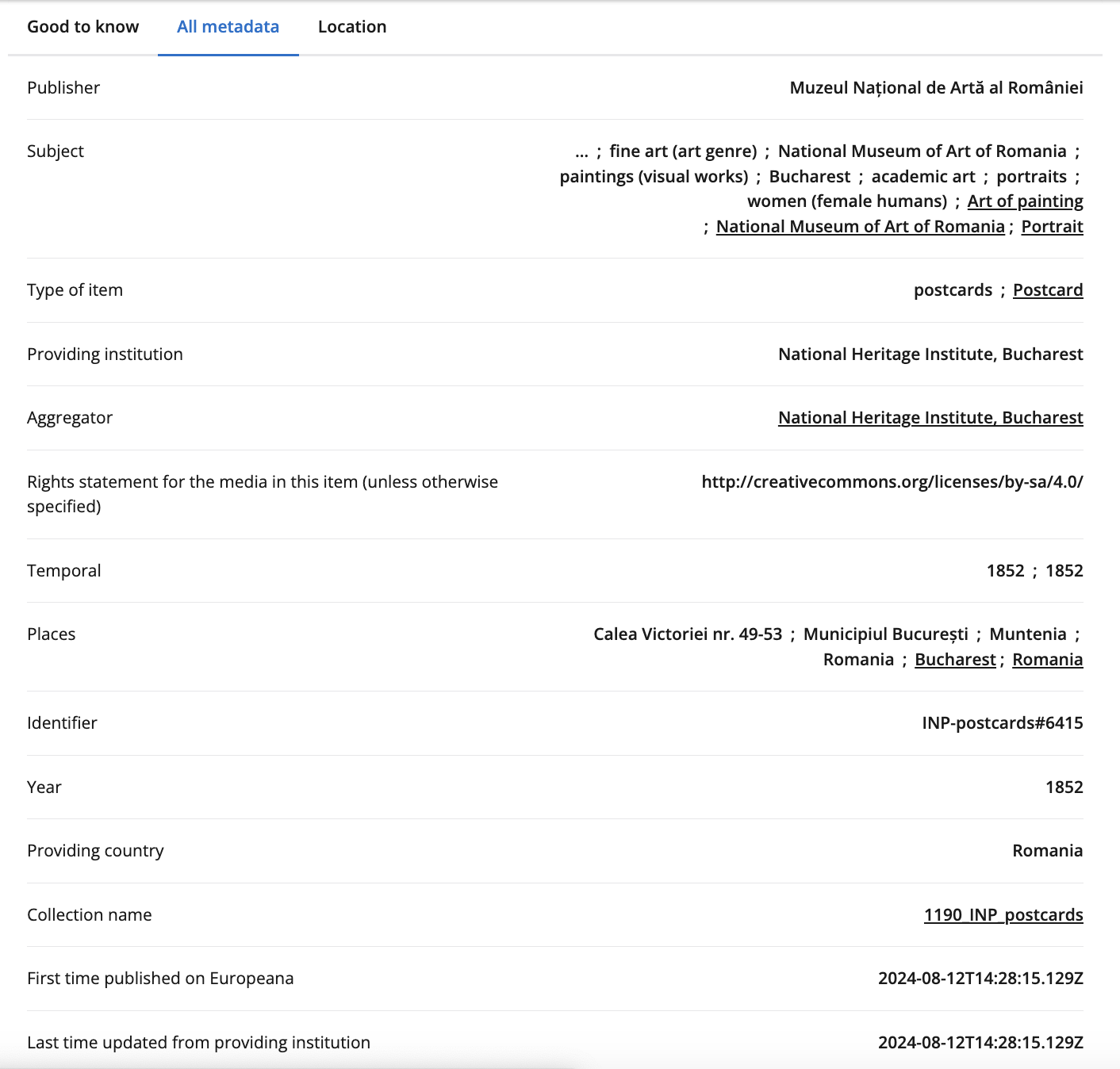
If we wanted to get this data programmatically, we could use the Europeana API, which provides access to the metadata for items in the collection.

To do this, we first need to get an API key from Europeana, which you can do by signing up for an account here https://pro.europeana.eu/pages/get-api.
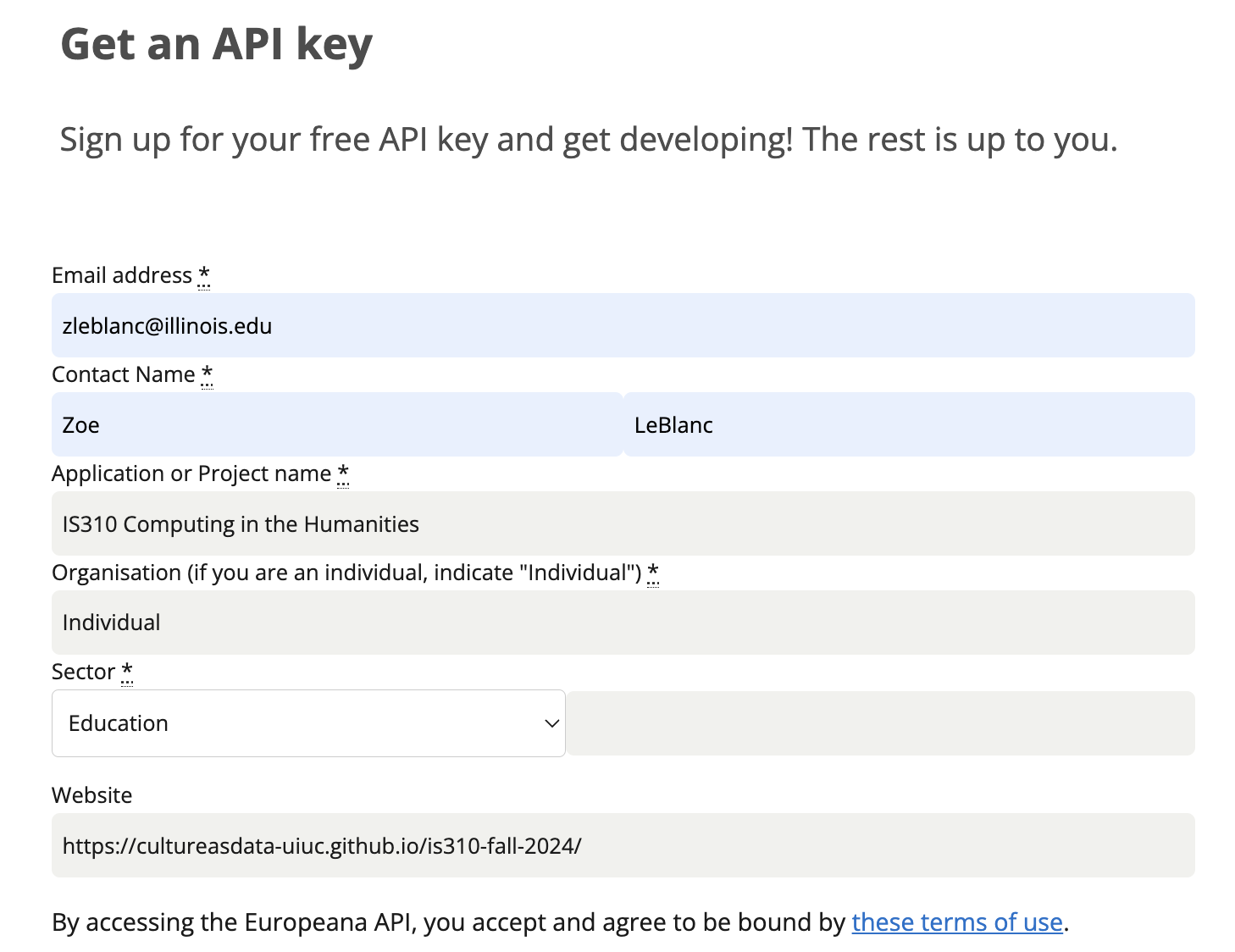
You’ll notice that this API requires more information to get a key than The One API. Many APIs want you to explain what you plan to use them for and also to include a website where you will be using the API. For Europeana, I would recommend using your @illinois.edu email address, saying that the Application or Project Name is IS310 Computing in the Humanities Course, and that the website is either your .github.io website or our course website https://cultureasdata-uiuc.github.io/is310-fall-2024/. Once you have applied, you should see your api key in your inbox in a few minutes.
While we could use requests to access these APIs, there’s also a Python library pyeuropeana that has been designed to work with the Europeana API. You can see the documentation for this library here https://rd-europeana-python-api.readthedocs.io/en/stable/index.html and the GitHub repository here https://github.com/europeana/rd-europeana-python-api/tree/master.
If we go to the Quickstart page in the documentation https://rd-europeana-python-api.readthedocs.io/en/stable/usage.html#, we can see that we can install the library with the following command:
pip install pyeuropeana
Then if we scroll down to Authentication we can start to see how we can use the library to authenticate with the Europeana API.
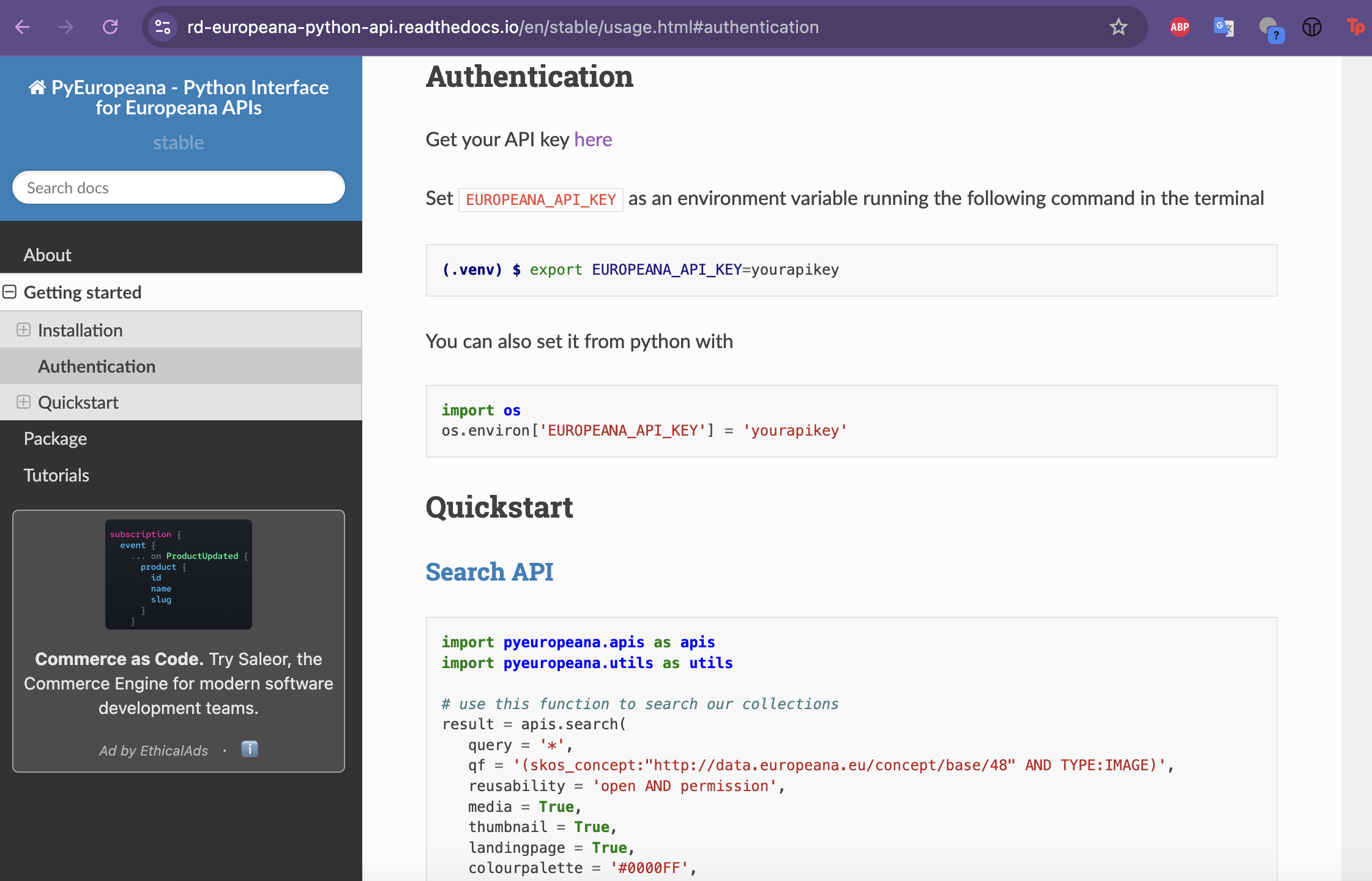
You’ll notice that this library wants you to use an environment variable rather than passing in the api key directly. While this approach is a bit confusing, we can still use our apikey library to store our api key as an environment variable.
import apikey
import os
apikey.save("EUROPEANA_API_KEY", "YOUR_API_KEY_HERE")
europeana_api_key = apikey.load("EUROPEANA_API_KEY")
os.environ['EUROPEANA_API_KEY'] = europeana_api_key
If you try using the pyeuropeana library with the api key stored as an environment variable, you may see the following error:
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
That is an issue with the numpy python library. To fix this, you can run the following command in your terminal:
pip uninstall numpy
It will ask you if you want to uninstall numpy, to which you should say y. Then you can reinstall numpy with the following command:
pip install "numpy==1.26.4"
You may also see the following error:
from PIL import Image
ModuleNotFoundError: No module named 'PIL'
This is because the pyeuropeana library uses the Pillow library, which is a fork of the PIL library. To fix this, you can install the Pillow library with the following command:
pip install Pillow
If you have any additional errors, please reach out to the instructors for help.
Now we can start exploring how to access data from the Europeana API using the pyeuropeana library. In particular, we are going to try out the search method, which allows us to search the Europeana collection for items that match a specific query.
This is the example from the documentation:
import pyeuropeana.apis as apis
import pyeuropeana.utils as utils
# use this function to search our collections
result = apis.search(
query = '*',
qf = '(skos_concept:"http://data.europeana.eu/concept/base/48" AND TYPE:IMAGE)',
reusability = 'open AND permission',
media = True,
thumbnail = True,
landingpage = True,
colourpalette = '#0000FF',
theme = 'photography',
sort = 'europeana_id',
profile = 'rich',
rows = 1000,
) # this gives you full response metadata along with cultural heritage object metadata
# use this utility function to transform a subset of the cultural heritage object metadata
# into a readable Pandas DataFrame
dataframe = utils.search2df(result)
And we can see that there’s a number of attributes we can use to filter our search, including query, qf, reusability, media, thumbnail, landingpage, colourpalette, theme, sort, profile, and rows. We can also see that we can use the utils.search2df method to transform the data into a Pandas DataFrame.
Let’s try a simpler example first though:
import pyeuropeana.apis as apis
response = apis.search(query="Galadriel")
print(response)
Which should show the following output:
{'apikey': 'tondflanrino',
'success': True,
'requestNumber': 999,
'itemsCount': 0,
'totalResults': 3,
'items': [{'completeness': 0,
'country': ['Italy'],
'dataProvider': ['Internet Culturale'],
'dcCreator': ['http://data.europeana.eu/agent/159584',
'Karunesh',
'Karunesh'],
'dcCreatorLangAware': {'def': ['http://data.europeana.eu/agent/159584',
'Karunesh'],
'en': ['Karunesh']},
'dcTitleLangAware': {'def': ['Galadriel'],
'en': ['Galadriel'],
'it': ['Galadriel']},
'edmConcept': ['http://data.europeana.eu/concept/soundgenres/Music'],
'edmConceptLabel': [{'def': 'Musik'},
{'def': 'Music'},
{'def': 'Musica'},
{'def': 'Muzyka'},
{'def': 'Musique'},
{'def': 'Música'}],
'edmConceptPrefLabelLangAware': {'de': ['Musik'],
...
'profile': None,
'rows': 12,
'cursor': '*',
'callback': None,
'facet': None}}
We can also print out the response.keys() to see all the keys in the response. You’ll notice this api has a totalResults key, which tells us how many items match our query, and an items key, which contains a list of dictionaries, each of which contains information about an item in the collection.
If we select one of the items, we can see that it has a number of keys, including completeness, country, dataProvider, dcCreator, dcCreatorLangAware, dcTitleLangAware, edmConcept, edmConceptLabel, edmConceptPrefLabelLangAware, and more. This data is similar to the data we saw on the Europeana website, and it includes information about the creator, title, and concept of the item.
We can also see in the Search API documentation what keys we should expect for our initial search request https://europeana.atlassian.net/wiki/spaces/EF/pages/2385739812/Search+API+Documentation#Response, as well as what data should return for each item https://europeana.atlassian.net/wiki/spaces/EF/pages/2385739812/Search+API+Documentation#Metadata-Sets. For example, if we wanted to see the item in the browser we would just need to use the guid key.
response['items'][0]['guid']
We could also try out the Entity API, which allows us to get more information about a specific entity in the collection. According to the api’s documentation https://europeana.atlassian.net/wiki/spaces/EF/pages/2324561923/Entity+API+Documentation, the Europeana collection has these types of entities:
- a person (or “agent”), for instance Lili Boulanger or Claude Debussy;
- a topic (or “concept”) like Art Nouveau, migration or Musique Concrète
- a place, for instance Perpignan, Bratislava or Arnhem
- a time period, for instance the 21st century
In the pyeuropeana documentation, there’s a section of tutorials, including one for using the Entity API https://rd-europeana-python-api.readthedocs.io/en/stable/tutorials_source/entity_api_tutorial.html.
According to this tutorial, we can use the entity.suggest method to get suggestions for a specific entity. For example, if we wanted to get suggestions for the entity Galadriel, we could use the following code:
response = apis.entity.suggest(
text = 'Galadriel',
TYPE = 'agent',
)
print(response)
However, we’ll see there’s no results for this query. We could try a different entity, like Tolkien, and see if we get any results.
response apis.entity.suggest(
text = 'Tolkien',
TYPE = 'agent',
)
print(response)
This should give the following output:
',
'ugc': [False],
'year': ['1989']}
{'@context': ['https://www.w3.org/ns/ldp.jsonld',
'http://www.europeana.eu/schemas/context/entity.jsonld'],
'type': 'ResultPage',
'total': 3,
'items': [{'id': 'http://data.europeana.eu/agent/60065',
'type': 'Agent',
'isShownBy': {'id': 'http://pbc.gda.pl/Content/20559/03.mp3',
'type': 'WebResource',
'source': 'http://data.europeana.eu/item/0940417/_nnbqsf5',
'thumbnail': 'https://api.europeana.eu/api/v2/thumbnail-by-url.json?uri=http%3A%2F%2Fpbc.gda.pl%2FContent%2F20559%2F03.mp3&type=SOUND'},
'prefLabel': {'en': 'J. R. R. Tolkien'},
'altLabel': {'en': ['J-R-R Tolkien',
'Tolkien',
'John Ronald Reuel Tolkien',
'John Tolkien',
'J.R.R Tolkien',
'J.R.R. Tolkien',
'John R. R. Tolkien']},
'dateOfBirth': '1892-01-03',
'dateOfDeath': '1973-09-02'},
{'id': 'http://data.europeana.eu/agent/60339',
'type': 'Agent',
'prefLabel': {'en': 'Christopher Tolkien'},
'altLabel': {'en': ['Christopher John Reuel Tolkien',
'Christopher Reuel Tolkien',
...
'dateOfDeath': '2020-01-16'},
{'id': 'http://data.europeana.eu/agent/79852',
'type': 'Agent',
'prefLabel': {'en': 'Tim Tolkien'},
'dateOfBirth': '1962-09-01'}]}
We could also look for concepts or places, like Literature or London, to see what results we get. However, to do that we need to change the TYPE parameter to concept or place.
response_concept = apis.entity.suggest(
text = 'Literature',
TYPE = 'concept',
)
response_place = apis.entity.suggest(
text = 'London',
TYPE = 'place',
)
Now we can start to see how we can use the pyeuropeana library to access data from the Europeana collection and also the value of using both APIs and wrappers. Specifically, in this instance we didn’t need to spend a lot of time researching the API endpoints and how to make requests to the API, as the library abstracted this process for us. However, we did need to spend time understanding how to use the library and how to work with the data it returned. This is a common tradeoff when working with APIs and wrappers, and it’s important to consider the benefits and drawbacks of each approach when working with APIs.
GETting Culture Across APIs Homework
Now that you understand how to work with APIs, it’s time to experiment and explore some new APIs. In your api-getting-data in your is310-coding-assignments repository, create a new script called getting_culture.py.
In the script you will be working with both the Europeana API and a new api of your choice. If you need inspiration, you can look at the following resources:
- https://github.com/chanonroy/cool-apis
- https://github.com/public-apis/public-apis
- https://apilist.fun/
- One of my personal favorites is SWAPI (the Star Wars API) https://swapi.dev/documentation
After you pick an API, read through the documentation and find a way to get data from it. For APIs that require authentication, make sure you authenticate and store your API keys locally. You can use either requests or python wrapper libraries, but the goal is to:
- Make a request to the API of your choice
- Print out the response
- And then, find related data about a specific item in the response in the Europeana collection
- Finally, print out the response for that item
Once you have the data from both APIs, you should then store just the item data in either as a JSON file or as a CSV file (choice is yours) with the filename that includes the API you selected.
Finally, push both your script and the data to your Github repository. Please remember to NOT include any private API keys! This is particular important with the Europeana api which will return your api key in the response, so make sure you filter that out before saving the data.
Once you have completed the assignment, please post a link to your api-getting-data folder in this GitHub discussion https://github.com/CultureAsData-UIUC/is310-fall-2024/discussions/10. Remember to include a brief description of the API you selected and why you chose it in your README.md file and to not push up any private API keys, virtual environments, or other sensitive information.
Additional Resources
- Snodgrass, Eric, and Winnie Soon. “API Practices and Paradigms: Exploring the Protocological Parameters of APIs as Key Facilitators of Sociotechnical Forms of Exchange.” First Monday, February 1, 2019. https://doi.org/10.5210/fm.v24i2.9553.
- Kazemi, Darius. “The Land before Modern APIs – Increment: APIs.” Increment, August 2020. http://localhost:3000/apis/land-before-modern-apis/.
- Loukissas, Yanni Alexander. All Data Are Local: Thinking Critically in a Data-Driven Society. MIT Press, 2019.
- Go Sugimoto, “Introduction to Populating a Website with API Data,” Programming Historian 8 (2019), https://doi.org/10.46430/phen0086.
- Patrick Smyth, “Creating Web APIs with Python and Flask,” Programming Historian 7 (2018), https://doi.org/10.46430/phen0072.
- Jeri Wieringa, “Getting Data,” DH Bridge, http://curriculum.dhbridge.org/modules/module03.html.
- Lauren Klein and Dan Sinykin, “Intro to APIs,” QTM340-Fall21, https://github.com/laurenfklein/QTM340-Fall21/blob/main/notebooks/class7-accessing-apis.ipynb.
- Melanie Walsh, “Intro to APIs,” Intro to Cultural Analytics, https://melaniewalsh.github.io/Intro-Cultural-Analytics/04-Data-Collection/05-What-Is-API.html.
-
Lane, Kin. “The History of APIs,” API Evangelist, https://history.apievangelist.com/. ↩
-
Jakob Jünger, “A Brief History of APIs,” in Handbook of Computational Social Science, Volume 2, by Uwe Engel, Anabel Quan-Haase, Sunny Xun Liu, and Lars Lyberg (Taylor & Francis, 2021), https://doi.org/10.4324/9781003025245-3. ↩
-
Freelon, Deen. “Computational Research in the Post-API Age.” Political Communication 35, no. 4 (October 2, 2018): 665–68. https://doi.org/10.1080/10584609.2018.1477506. ↩
-
Acker, Amelia, and Adam Kreisberg. “Social Media Data Archives in an API-Driven World.” Archival Science 20, no. 2 (June 1, 2020): 105–23. https://doi.org/10.1007/s10502-019-09325-9. ↩
-
“Europeana,” Wikipedia, https://en.wikipedia.org/wiki/Europeana and Roued, Henriette. “Europeana API Explained.” https://roued.com/portfolio/europeanas-api-explained/. ↩