Introduction to Structuring Data
In the last lesson, we learned the foundations of EDA and how to use Pandas and Altair to explore and visualize data. In this lesson, we will be focusing on unstructured text data and how we can structure it for analysis.
In the previous lesson, you might have noticed that we used the following code to manipulate the novel titles:
nyt_bestsellers_df = nyt_bestsellers_df.rename(columns={'title': 'nyt_title'})
nyt_bestsellers_df['title'] = nyt_bestsellers_df['nyt_title'].str.capitalize()
Part of what makes Pandas so powerful is that it has a number of built-in methods for working with string data, and you can access them by using the .str accessor method. An in-depth discussion of these methods are available on the Pandas documentation website https://pandas.pydata.org/docs/user_guide/text.html, but I’ve also summarized many of the more popular methods below in this table:
| Pandas String Method | Explanation |
|---|---|
df[‘column_name’].str.lower() |
lowercase all the values in a column |
df[‘column_name’].str.upper() |
uppercase all the values in a column |
df[‘column_name’].str.replace(‘old_string’, ‘new_string’) |
replace all instances of ‘old_string’ with ‘new_string’ in a column |
df[‘column_name’].str.split(‘delimiter’) |
split a column by ‘delimiter’ like a comma or period, or really anything |
df[‘column_name’].str.strip() |
remove leading and trailing whitespace from a column |
df[‘column_name’].str.len() |
count the number of characters in a column |
df[‘column_name’].str.contains(‘pattern’) |
check if a column contains a particular pattern |
df[‘column_name’].str.startswith(‘pattern’) |
check if a column starts with a particular pattern |
df[‘column_name’].str.endswith(‘pattern’) |
check if a column ends with a particular pattern |
df[‘column_name’].str.find(‘pattern’) |
find the first occurrence of a particular pattern in a column |
df[‘column_name’].str.findall(‘pattern’) |
find all occurrences of a particular pattern in a column |
df[‘column_name’].str.count(‘pattern’) |
count the number of occurrences of a particular pattern in a column |
df[‘column_name’].str.extract(‘pattern’) |
extract the first occurrence of a particular pattern in a column |
df[‘column_name’].str.extractall(‘pattern’) |
extract all occurrences of a particular pattern in a column |
df[‘column_name’].str.join(list) |
join a list of strings with a delimiter |
In our case, we used the str.capitalize() method to capitalize the first letter of each word in the title column. This is a simple example, but it shows how powerful Pandas can be for working with text data.
Today we will be exploring more advanced methods for working with text data, and how we can structure it for analysis. But first, we need some text.
First, let’s create a new folder in our is310-coding-directory called text-analysis, and in it create a new Jupyter Notebook called IntroTextAnalysis.ipynb.
In that notebook, you should load in both the nyt_bestsellers_df and novels_df DataFrames that we created in the last lesson, and then once again merge them together.
combined_novels_nyt_df = novels_df.merge(nyt_bestsellers_df, how='left', on=['author', 'title'])
Now that we have our DataFrame, we can start to look more closely at some of the columns. Specifically, we could take a look at the columns with url in the DataFrame. We have four: gr_url, wiki_url, pg_eng_url, and pg_orig_url. We could subset our novels_df to only these columns and then use the .describe() method to see how many unique values we have.
combined_novels_nyt_df[['gr_url', 'wiki_url', 'pg_eng_url', 'pg_orig_url']].describe()
Which gives us the following output:
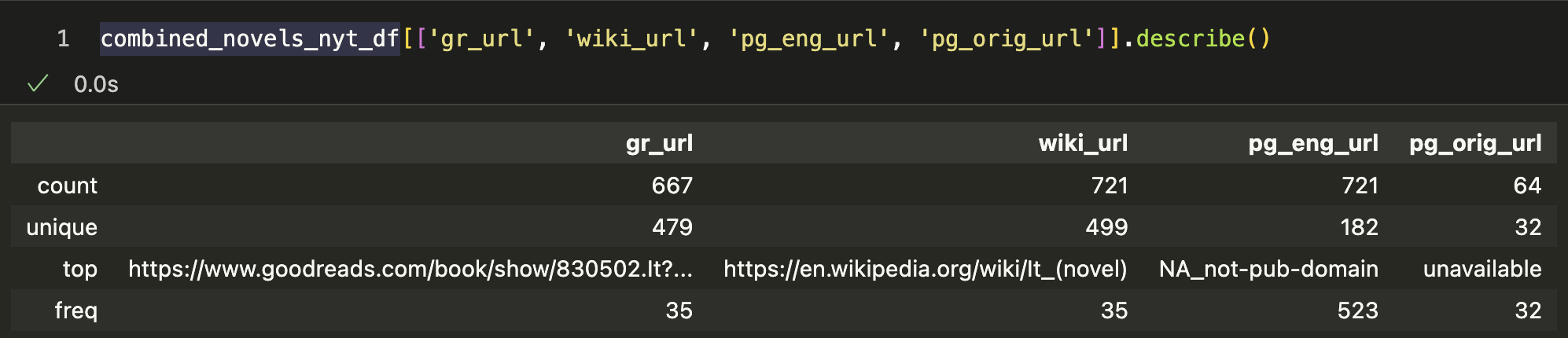
This gives us a sense of the distribution of the URLs in our dataset. For example, we can see that the pg_orig_url column has only 64 non-null values, which means that there are 657 missing values. We could also just explore one row to get a better sense of what these URLs look like.
combined_novels_nyt_df[['gr_url', 'wiki_url', 'pg_eng_url', 'pg_orig_url']][0:1].to_dict()
Which gives us the following output:
{'gr_url': {0: 'https://www.goodreads.com/book/show/3836.Don_Quixote?from_search=true&from_srp=true&qid=Npjwg6DCCM&rank=1'},
'wiki_url': {0: 'https://en.wikipedia.org/wiki/Don_Quixote'},
'pg_eng_url': {0: 'https://www.gutenberg.org/cache/epub/996/pg996.txt'},
'pg_orig_url': {0: 'https://www.gutenberg.org/cache/epub/2000/pg2000.txt'}}
This detail is helpful but let’s first breakdown the different methods I’m using to get a sense of the data. First, I’m using the two square brackets to subset the DataFrame to only the columns I want, using the exact column names. Then I’m using square brackets again to select the index of the first row of the DataFrame. Finally, I’m using the to_dict() method to convert the DataFrame to a dictionary, which makes it easier to read the full values in the output.
If we copy the pg urls into our browser we can see that pg_orig_url is the original Spanish text of the novel, while pg_eng_url is the English translation. We could use either of these urls to scrape the text of the novels and then analyze them further.
Let’s test that out with the pg_eng_url column. We can use the requests library to get the text of the novel. We are not using BeautifulSoup here since we are just essentially downloading the text file and there is no HTML to parse.
import requests
url = novels_df['pg_eng_url'][0]
response = requests.get(url)
if response.status_code == 200:
text = response.text
print(text[:500]) # Print the first 500 characters of the text
else:
print(f"Failed to retrieve text. Status code: {response.status_code}")
This code should print the following output:
The Project Gutenberg eBook of Don Quixote
This ebook is for the use of anyone anywhere in the United States and
most other parts of the world at no cost and with almost no restrictions
whatsoever. You may copy it, give it away or re-use it under the terms
of the Project Gutenberg License included with this ebook or online
at www.gutenberg.org. If you are not located in the United States,
you will have to check the laws of the country where you are located
before using this eBook.
Now we can see that we have successfully scraped the text of the novel! Our next step is to do this for all the novels in our dataset. We could create a new DataFrame to store the text of each novel, but we also want to be careful about how we handle missing values.
To do this we should loop through the combined_novels_nyt_df DataFrame and check if the pg_eng_url column is not null. If it is not null, we can scrape the text and store it in a new DataFrame. Here’s how we could do that:
import requests
def get_text(url):
# Check if the url is not null
if pd.notna(url):
# Try getting the text from the url
try:
response = requests.get(url)
# Check if the response is successful and return the text. Else return None
if response.status_code == 200:
return response.text
except Exception as e:
return None
return None
Now to run this function we could loop through our DataFrame, similar to how we have in the past but we cannot simply just loop through a DataFrame like we would a list:
for row in combined_novels_nyt_df:
print(row)
If you run this code, you will see that it prints out the column names of the DataFrame, not the rows. This is because a DataFrame is a more complex data structure than a list, and you need to use the iterrows() method to loop through the rows of a DataFrame.
for index, row in combined_novels_nyt_df.iterrows():
print(row)
Now we can access each row and therefore each column in the DataFrame. We can use this to apply our get_text() function to the pg_eng_url column.
texts = []
for index, row in combined_novels_nyt_df.iterrows():
text = get_text(row['pg_eng_url'])
texts.append(text)
# Create a new DataFrame with the text of each novel
novel_texts_df = pd.DataFrame({'text': texts})
# Merge the new DataFrame with the original DataFrame
combined_novels_nyt_df = pd.concat([combined_novels_nyt_df, novel_texts_df], axis=1)
You’ll notice here that I’m creating an empty list called texts and then appending the text of each novel to this list. This is a common pattern in Python, and it’s a good way to store the results of a loop. Once we have all the texts, we can create a new DataFrame called novel_texts_df and then merge this DataFrame with the original DataFrame.
However, there’s an even more efficient way to do this using the apply() method, documentation available here https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html. This method applies a function to each row of a DataFrame, which is exactly what we want to do in this case.
combined_novels_nyt_df['eng_text'] = combined_novels_nyt_df['pg_eng_url'].apply(get_text)

You’ll notice in this graphic that this apply() method is similar to the groupby method we learned in the last lesson. It also indicates that apply is a method that can take arguments, specifically the axis argument which can be set to 0 or 1 to apply the function to the rows or columns of the DataFrame. In our case we are selecting one column, so we are using apply on a Series, which is why we don’t need to specify the axis argument.
However, we could also do the following. Say we only wanted to get texts that existed in both English and the original language. We could update our get_text function to take two urls and then apply it to the DataFrame like this:
def get_text(row):
eng_url = row.pg_eng_url
orig_url = row.pg_orig_url
# Check if the url is not null
if pd.notna(eng_url) and pd.notna(orig_url):
# Try getting the text from the url
try:
eng_text_response = requests.get(eng_url)
# Check if the response is successful and return the text. Else return None
if eng_text_response.status_code == 200:
return eng_text_response.text
except Exception as e:
return None
return None
combined_novels_nyt_df['pg_eng_text'] = combined_novels_nyt_df.apply(get_text, axis=1)
Here we are passing in the entire row to the function, which is useful if we need to use data from multiple columns to do our transformations. You might see a warning though when you run this code:
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
This is telling us that we are trying to set a value on a copy of the DataFrame, which is not recommended. To avoid this warning, we can use the loc method to set the value on the original DataFrame.
combined_novels_nyt_df.loc[:, 'pg_eng_text'] = combined_novels_nyt_df.apply(get_text, axis=1)
Now we are telling Pandas to select the entire DataFrame and then set the value of the pg_eng_text column to the result of the get_text function, but specifically using the loc method and : to select the entire DataFrame.
We could even updated our code to check for the status code of the orig_url as well, and then return both texts if they are successful.
def get_text(row):
eng_url = row.pg_eng_url
orig_url = row.pg_orig_url
# Check if the url is not null
if pd.notna(eng_url) and pd.notna(orig_url):
# Try getting the text from the url
try:
eng_text_response = requests.get(eng_url)
orig_text_response = requests.get(orig_url)
# Check if the response is successful and return the text. Else return None
if eng_text_response.status_code == 200 and orig_text_response.status_code == 200:
return eng_text_response.text, orig_text_response.text
except Exception as e:
return None, None
return None, None
combined_novels_nyt_df[['pg_eng_text', 'pg_orig_text']] = combined_novels_nyt_df.apply(get_text, axis=1, result_type='expand')
Now we are returning both the English and original texts if they are successful. We are also using the result_type='expand' argument to expand the result of the function into separate columns.
While looping is still useful, it is highly recommended to use the apply() method when working with DataFrames in Pandas. It is more efficient, and a good way to get started with more advanced data manipulation in Pandas. You can see the time comparison between different methods for looping and applying functions to DataFrames in this graphic below:
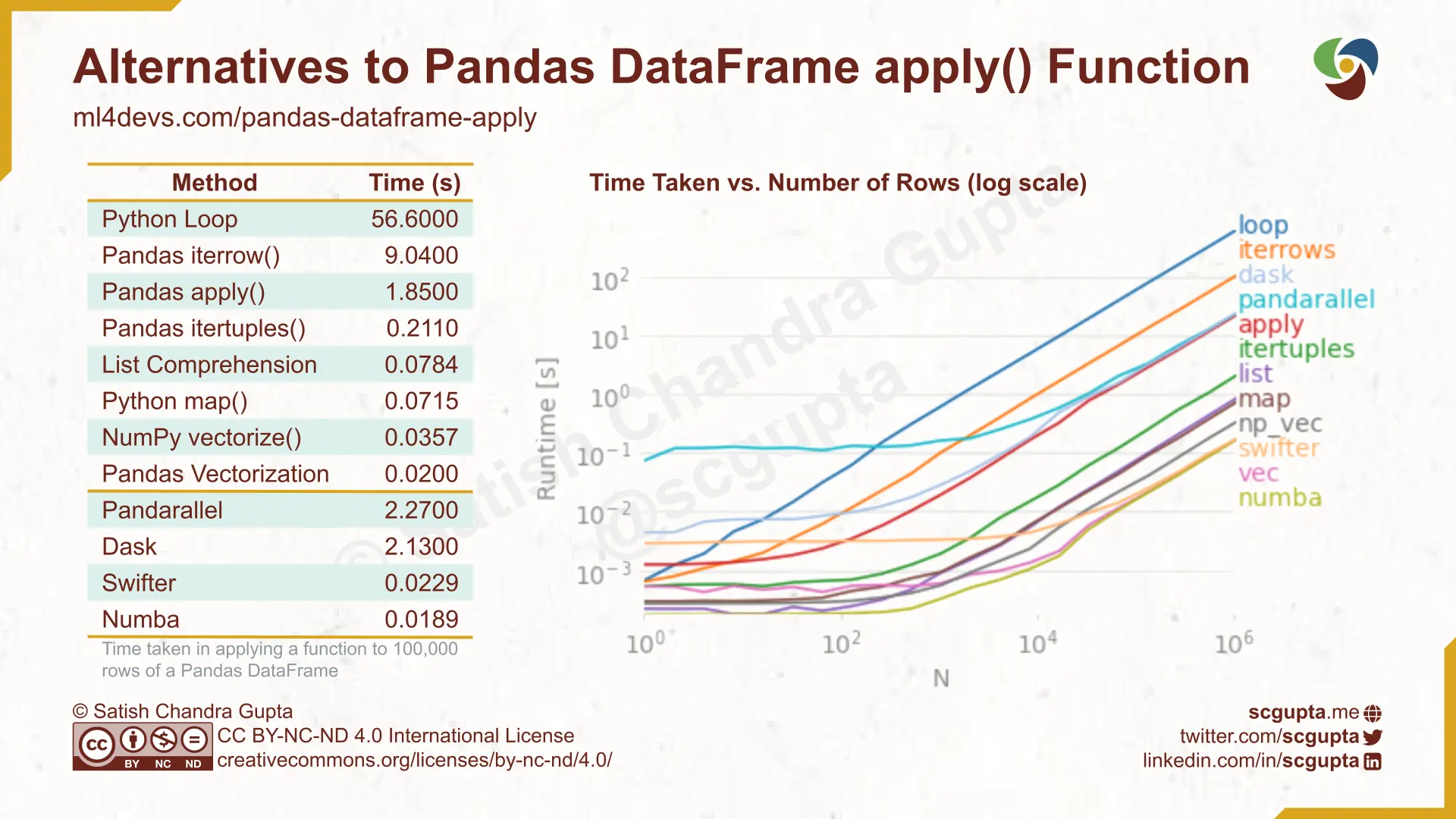
In terms of our code, there’s lots of ways we might end up writing this function. For example, we could use a try and except block to catch any errors that might occur when we try to get the text. We could also use the pd.notna() function to check if the url is not null. Some considerations we want to keep in mind when writing code:
- Readability: Is the code easy to read and understand?
- Efficiency: Is the code efficient and does it run quickly?
- Robustness: Does the code handle errors and edge cases gracefully?
- Reusability: Can the code be reused in other parts of the project?
In our case, that might mean that we rewrite our current code to be a function called get_book_text that takes in simply the url and returns the text of the book in a try and except block.
def get_book_text(url):
if pd.notna(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except Exception as e:
pass
return None
from tqdm import tqdm
tqdm.pandas(desc="Getting English Texts")
combined_novels_nyt_df.loc[:, 'pg_eng_text'] = combined_novels_nyt_df.pg_eng_url.progress_apply(get_text)
tqdm.pandas(desc="Getting Original Texts")
combined_novels_nyt_df.loc[:, 'pg_orig_text'] = combined_novels_nyt_df['pg_orig_url'].progress_apply(get_text)
In the code above, I’m also using a new library, the tqdm library, to create a progress bar for the apply() method. This is a good way to keep track of the progress of the function, especially if it is taking a long time to run, which can happen when web scraping. You can read more about tqdm here https://tqdm.github.io/.
Unstructured Data
So far we have primarily been focused on either collecting and curating data, or exploring it using data visualization and descriptive statistics. But a huge part of working with cultural data is actually analyzing it.
To do that though requires understanding how computational methods can help us find patterns and outliers in cultural data. Here’s the graph from Ted Underwood that gives us some idea of the range of computational methods available to humanists (and remember this was published in 2015, so there are even more options now):

When working with data, you’ll often come across the terms “structured” and “unstructured” data. There are lots of definitions online, like this graph below:

This graph is technically correct, but it is also a bit confusing when you think about it (even highly organized data can be difficult to analyze for example and why can’t things like email be analyzed in spreadsheets?).
In our last lesson, we explored how some of the values in these spreadsheets are categorical values and how some are numerical values. And finally how some are a bit in between, like year which is technically represented as a number and we could treat it as either a continuous or discrete value (so for example, if it is a date that is continuous, but if it is a year it is discrete), or we could treat it as a categorical value that is ordinal (i.e. is a category with an implied order).
The big thing though is that all these values are structured. We do not need to do any processes to turn these values into data to analyze. We might group them, we might filter them, we might fill in missing values, and we can plot them – but essentially this is a dataset ready to be analyzed.
Now that we have the texts of novels in our dataset, we have unstructured data. This is data that is not easily searchable or analyzed. It is often in the form of text, images, or audio, and it requires additional processing to make it useful. This is where text analysis comes in and specifically we need to go through a process of curating and cleaning the data from unstructured to structured data, similar to this graph below:

Structuring Cultural Data
Today we will be working with structuring text data, but many of the lessons we learn here can be applied to other types of unstructured data. For example, we could use similar methods to structure images or audio data for analysis.
To structure this data, we need to think about how we can break it down into smaller, more manageable pieces. Now it’s worth noting that there is no one right way to structure data, and it often depends on your goals and the data you have. A lot of what we are discussing today are common approaches in text analysis, and increasingly form the bedrock of both machine learning and artificial intelligence.
Text analysis is a very broad term for a whole set of practices and overlapping disciplines and fields, some of which are shown in this figure below:

However, rather than trying to define text analysis as a whole, I find a more helpful distinction is talking about information extraction versus information retrieval. These are two of the most common ways to structure text data, and they are often used in combination.
Information Retrieval (IR):
Information retrieval first developed in the 1950s and 1960s (remember Vannevar Bush and the Memex!) and its goal is to find relevant documents for a user’s needs or queries, which is why it is most often associated with search engines. It requires parsing textual information and finding patterns in the text.
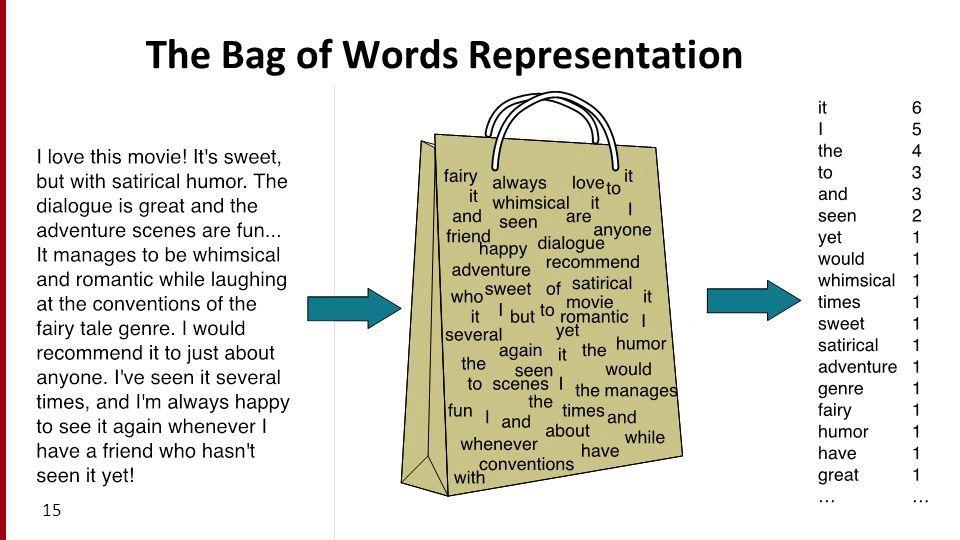
The key thing to remember about IR is that it is not necessarily understanding the content of those documents but finding relevant ones. This is why it is often used for text classification of documents, and it can be done without understanding syntax and treating documents as a “bag of words.”
Information Extraction (IE)
Information Extraction (or IE) is a bit different than IR. It is about extracting structured information from unstructured text. This is a bit more complex than IR, and it often involves things like Named Entity Recognition (or NER) and Sentiment Analysis.
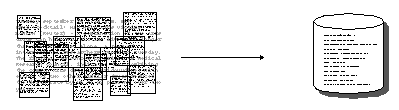
It first developed in the 1990s and is focused on extracting specific features from documents. It requires both syntactic and semantic analysis, and it is often used in fields like Natural Language Processing (NLP) and Computational Linguistics.
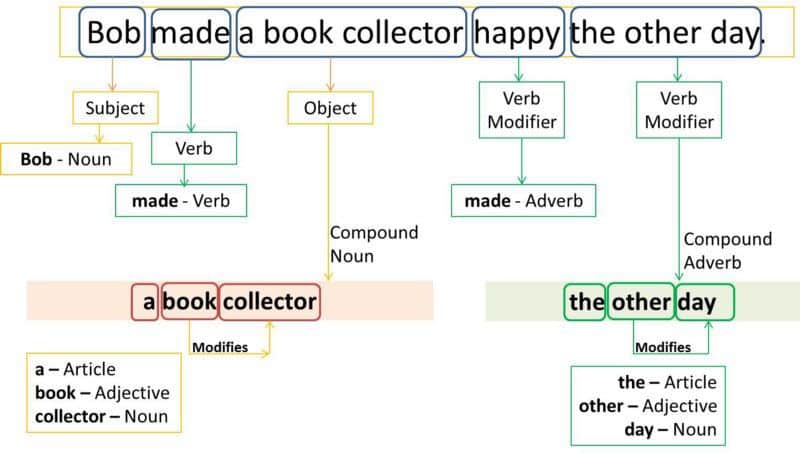
Text Analysis with Pandas
Now that we have a sense of the different potential overall goals of text analysis, let’s start with a simple example using Pandas. We can start by counting the number of words in each novel in our dataset. Though that of course raises a question of what is a word?
Let’s start off with the easiest way we can do that is by counting the number of characters in each row of the eng_text column. We can do this using the str.len() method in Pandas.
combined_novels_nyt_df['novel_length'] = combined_novels_nyt_df['eng_text'].str.len()
This code gives us a sense of the length of each novel, but it is not a perfect measure of the number of words. Specifically it is counting the length of the sequence in each cell in the eng_text column, which includes spaces and punctuation. So it is more of a measure of the number of characters in each novel.
To get a more accurate word count, we could split the text into words and then count the number of words. The easiest way to do this is to split the text on spaces and then count the number of elements in the resulting list, which we can do with the following code:
combined_novels_nyt_df['novel_numb_words'] = combined_novels_nyt_df['eng_text'].str.split().apply(len)
This code is using the str.split() method to split the text on spaces. Then we are again using the apply() method, but this time to apply the len function to each row of the DataFrame. With apply we can both call functions we have created, as well as built-in functions like len. We now have a more accurate measure of the number of words in each novel, but our approach is only one way that we can start to structure our text data. Indeed, what we are engaging in is something in Natural Language Processing (NLP) called tokenization.
Tokenization
Tokenization is the process of breaking up text into smaller units, which are often called tokens, which can be words, phrases, or characters, rather than just simply calling them words. You can see an example in this figure:
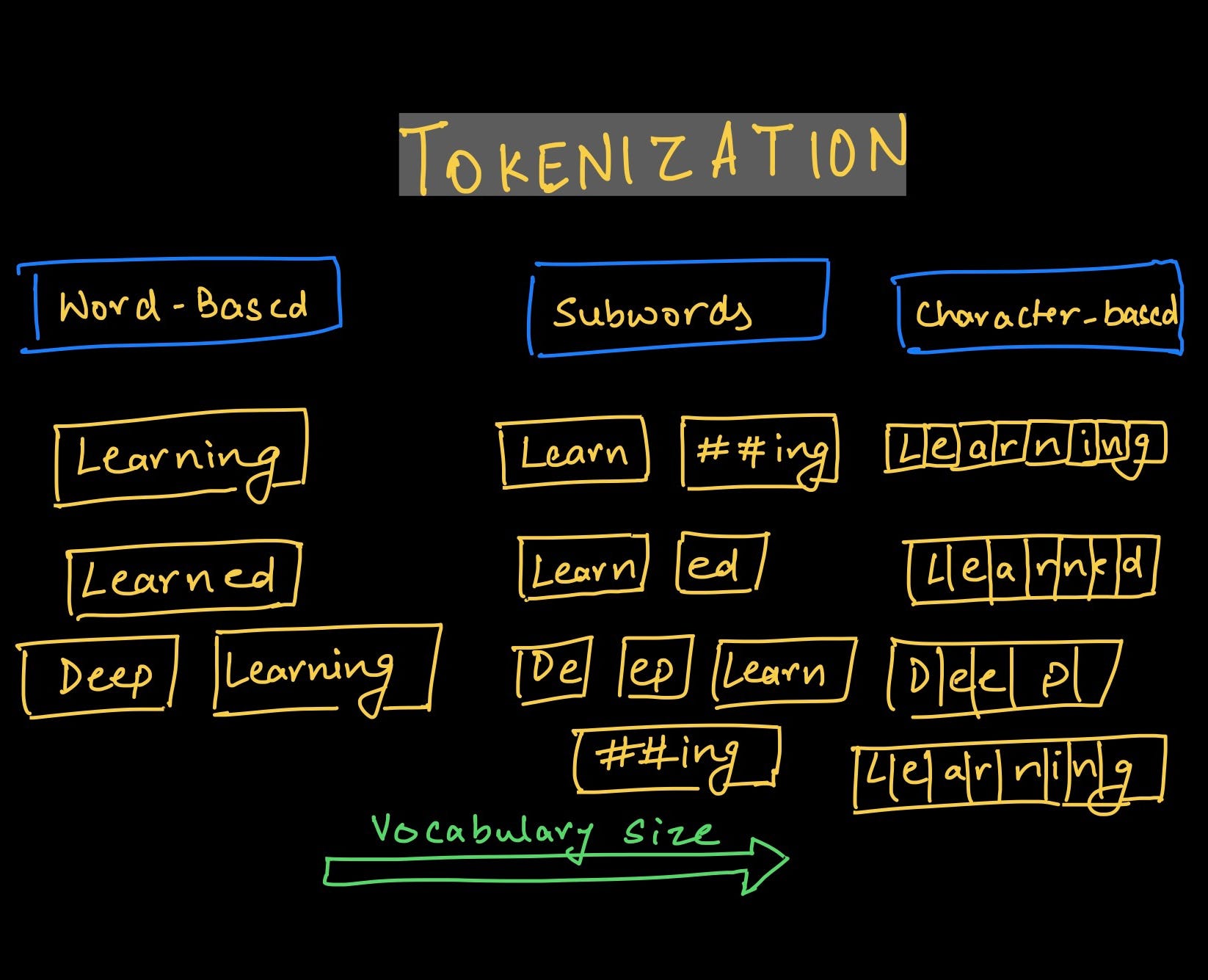
In the field of corpus linguistics, the term “word” is generally seen as too abstract, so they developed the terms of a “token” or “type.” For example, is the word “run” the same as “running” or “ran”? In corpus linguistics, we would say that these are all different tokens, but they are the same type.
Origins of Tokenization
The origins of modern tokenization go back to the 1950s and 1960s, with the origins of information retrieval and information extraction. However, the practice has been around for much longer, and it is a key part of the field of corpus linguistics.
One of the most important scholars was George Zipf, who in the 1930s revealed that in any corpus, the most common word appears about twice as often as the second, three times as often as the third, and so on. This distribution pattern is known as Zipf’s Law and underscores the importance of tokenization in understanding word frequency.
To get a sense of this principle, we are going to briefly explore one of the older libraries for text analysis, NLTK.

NLTK was first created in the late 1990s by Steven Bird and Edward Loper at the University of Pennsylvania. It was initially created to further research in corpus linguistics and natural language processing, but has since become a popular tool for text analysis in the humanities.
The library NLTK has a helpful built in Class called FreqDist that takes a list of words and outputs their frequency in a corpus http://www.nltk.org/api/nltk.html?highlight=freqdist
Let’s try it out with a subset of our data. Remember to do pip install nltk.
from nltk import word_tokenize
from nltk import FreqDist
tokens = FreqDist(sum(combined_novels_nyt_df[0:2]['pg_eng_text'].map(word_tokenize), []))
tokens.plot(30)
We should get a graph that looks like this:
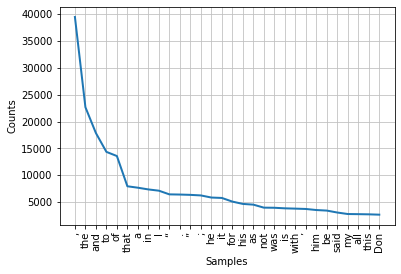
In this graph, if we had used all the words we would see this trend continue, like in the graph below.

This is what Zipf’s law looks like in reality, and you might be interested to learn that Zipf discovered this pattern when he was analyzing the frequency of words in James Joyce’s Ulysses in the 1930s (which is considered one of the first computing in the humanities projects!).
Ultimately, understanding this core textual phenomenon is essential: common words dominate text, and their distribution often fits a special type of scale called a logarithmic scale, which is better suited than a linear scale for visualizing data with extreme differences in frequency. A logarithmic scale compresses larger values more than smaller ones, making it easier to see patterns in data where a few items are very frequent, and most are rare. This pattern reflects the ‘rich get richer’ principle, which we also see in other systems, such as citation networks or social media, where a small number of items gain most of the attention.
Knowing about Zipf’s law is not only important for ensuring we have accurate analysis but also because the distribution of words in a text can help us answer different types of questions in the humanities. For example, if we use high frequency words we can often identify the authorship or style of a text1, and if we use low frequency words we can often identify the ideas of a text, whether’s it’s a genre of a novel or the themes of a poem or the topic of a news article. You can read more about the power of counting words here in another of Underwood’s blog posts https://tedunderwood.com/2013/02/20/wordcounts-are-amazing/.
Tokenization & Interpretation
Now that we understand the importance of how we count words, we can get into the interpretive choices that we make when we tokenize text.
There are many different ways to tokenize text, and the choice of tokenization method can have a big impact on the results of your analysis. Some common choices include:
- Should words be lowercased? Remember computers are case sensitive.
- Should punctuation be removed? Many often do this when “cleaning” data but it also removes important information.
- Should numbers be replaced by some placeholder? This is often done to remove noise from the data, though again it presents tradeoffs.
- Should words be stemmed (also called lemmatization)? This is a process of reducing words to their base or root form, which can help with analysis but also can remove important information.
- Should bigrams or other multi-word phrase be used instead of or in addition to single word phrases? This can help with understanding context but also can make analysis more complex and slower.
- Should stop-words (the most common words) be removed? This is often done to remove noise from the data, but it can also remove important information.
- Should rare words be removed? This might be helpful but means we might lose what is distinctive about a text.
These choices are just some of the considerations you might make when tokenizing text, and we often combine them in different ways.
We can try these out with our dataset. For example, would we get a different number of counts if we used NLTK’s tokenizer versus simply splitting on spaces?
def tokenize_text(text):
if pd.notna(text):
return word_tokenize(text)
else:
return []
combined_novels_nyt_df['tokenized_text'] = combined_novels_nyt_df['eng_text'].apply(tokenize_text)
Now we can compare the number of words in each novel using the split method versus the word_tokenize method.
combined_novels_nyt_df['split_numb_words'] = combined_novels_nyt_df['eng_text'].str.split().apply(len)
combined_novels_nyt_df['tokenized_numb_words'] = combined_novels_nyt_df['tokenized_text'].apply(len)
If we compared across both just doing the str.len, the str.split, and the word_tokenize we would see that the word_tokenize method is the most accurate, but also the slowest. This is because it is doing a lot more work than just splitting on spaces, and it is also doing a lot more work than just counting the length of the string.
In this graph, you can select the tokenization methods in the legend but we can start to get a sense of the differences in the number of words in each novel.
We could also look at the frequency of actual terms to get a sense of why tokenization matters so much. For example, we could count the number of times the words they, she, and he appear in each novel, using the str.count() method in Pandas, which counts the number of occurrences of a substring in a string.
combined_novels_nyt_df['they_counts'] = combined_novels_nyt_df['eng_text'].str.count('they')
combined_novels_nyt_df['she_counts'] = combined_novels_nyt_df['eng_text'].str.count('she')
combined_novels_nyt_df['he_counts'] = combined_novels_nyt_df['eng_text'].str.count('he')
Now we can plot the data.
# Plot the data
combined_novels_nyt_df[['they_counts', 'she_counts', 'he_counts']].plot()
Which produces the following graph:
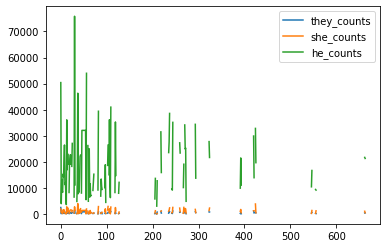
You’ll notice that he is much more frequent than the other two pronouns. Now this might because of the novels we have in our dataset, but it could also be because of the way we are counting the words. To understand more let’s dig into text analysis with Python more generally.
Now we can do the same pronoun analysis as before, but with our tokenized text. To do that we need to use the Counter class from the collections module in Python to count the number of times each pronoun appears in the tokenized list of words.
from collections import Counter
combined_novels_nyt_df['they_counts'] = combined_novels_nyt_df['tokenized_text'].apply(lambda tokens: Counter(tokens)['they'])
combined_novels_nyt_df['she_counts'] = combined_novels_nyt_df['tokenized_text'].apply(lambda tokens: Counter(tokens)['she'])
combined_novels_nyt_df['he_counts'] = combined_novels_nyt_df['tokenized_text'].apply(lambda tokens: Counter(tokens)['he'])
# Plot the counts
combined_novels_nyt_df[['they_counts', 'she_counts', 'he_counts']].plot()
This will give us a similar graph to before, but now we are counting words instead of just string matching, which is more accurate since the letters he could be part of another word (in this case they and she even!).
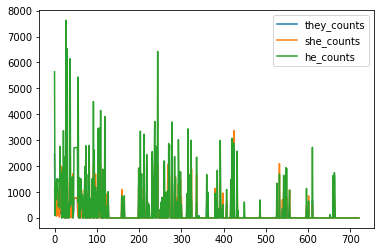
This graph is a bit hard to read, but you can start to see that he is no closer to the range of the other pronouns. We could also use Altair to inspect a bit closer. However, to replicate the plot graph, requires reshaping our data and specifically something called a melt operation.
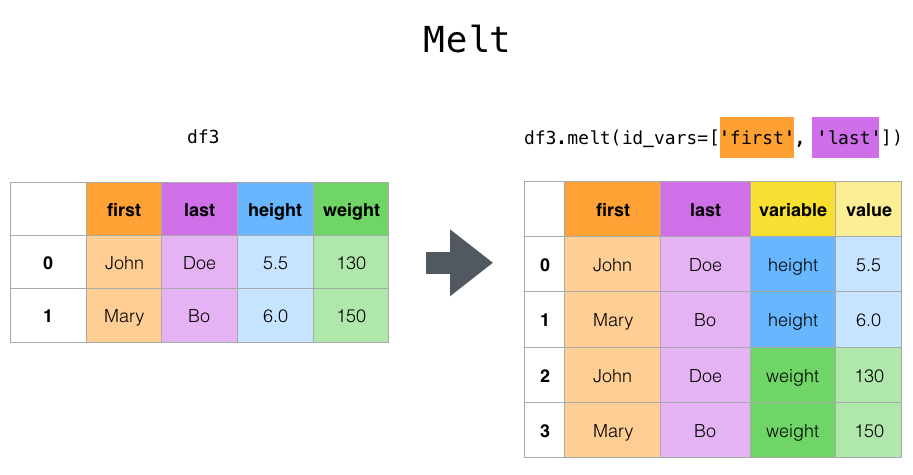
Melting in Pandas is a way to reshape your data from wide to long, since sometimes you want to look at the relationship between multiple columns. In this case, we are melting the they_counts, she_counts, and he_counts columns into with the name of the column in the var_name column and the value of the column in the value_name column, respectively (in this case pronoun and pronoun_counts). You can read more about melting here here https://pandas.pydata.org/docs/user_guide/reshaping.html#reshaping-by-melt.
melted_df = pd.melt(combined_novels_nyt_df, id_vars=['title', 'author', 'pub_year', 'genre'], value_vars=['they_counts', 'she_counts', 'he_counts'], var_name='pronoun', value_name='pronoun_counts')
alt.Chart(melted_df).mark_line().encode(
x='title:N',
y='pronoun_counts:Q',
color='pronoun:N',
tooltip=['title', 'author', 'pub_year', 'genre', 'pronoun_counts']
)
In this code we are using the melt() method by telling it to combine the they_counts, she_counts, and he_counts columns into two columns: one for the pronoun and one for the counts. Then we are visualizing this new DataFrame by passing into the Altair Chart class, and telling the chart to plot the pronoun counts for each novel.
Such analysis is helpful, but we could even start to form research questions. For example, are the patterns we are seeing consistent across genre? To do this we could use genre instead of title in the x axis of the chart.
alt.Chart(melted_df[melted_df.genre != "na"]).mark_bar().encode(
x='genre:N',
y='sum(count):Q',
color='pronoun:N',
tooltip=['title', 'author', 'pub_year', 'genre', 'count']
)
And now we should see the follow chart:
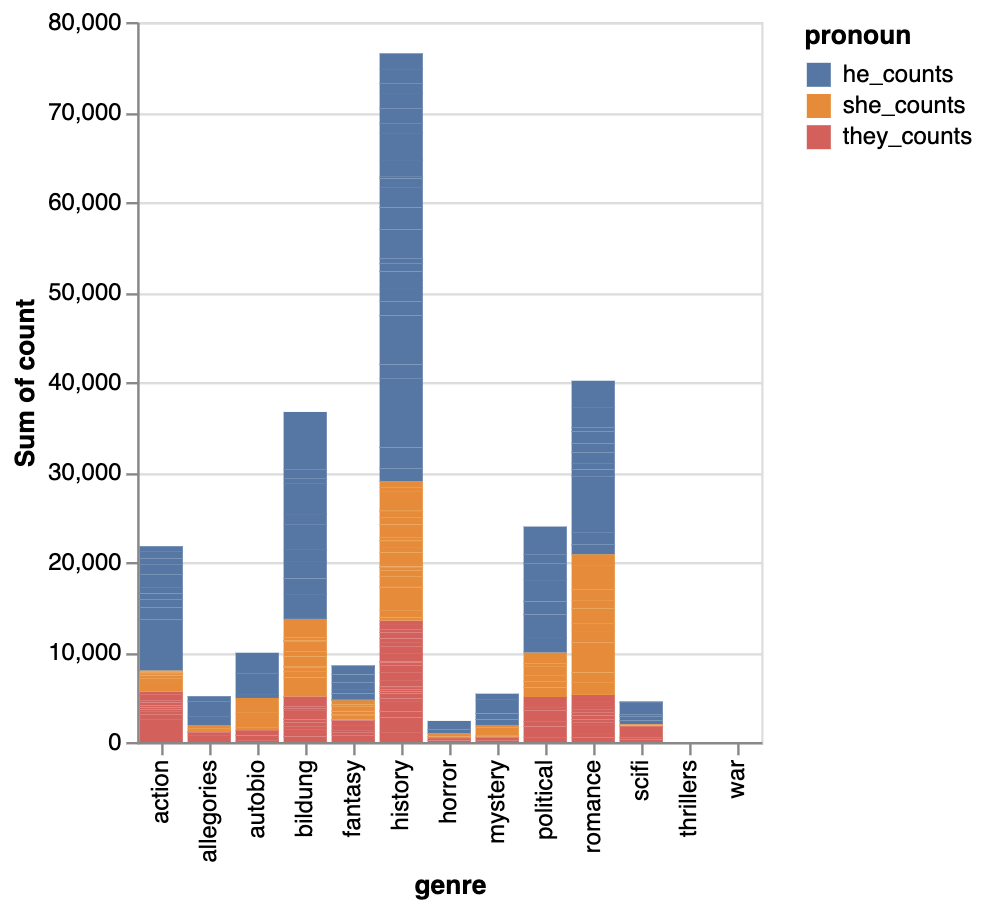
Next if we were doing EDA we might try to normalize these counts by both the number of words in a novel and the number of novels in a genre. This would give us a better sense of the relative frequency of these pronouns in each genre. But there’s still more interpretative tokenization questions we might want to address first.
Lemmatizing/Stemming
Mentioned earlier, lemmatizing and Stemming are both ways of reducing words to their root form to make them more normalized for analysis. Lemmatizing is the process of reducing words to their base form, while stemming is the process of reducing words to their stem, demonstrated in the figure below:

The NLTK library we used for FreqDist also comes with code to do stemming and lemmatization. We can use the PorterStemmer class to stem words and the WordNetLemmatizer class to lemmatize words. You can read more about these classes here https://www.nltk.org/api/nltk.stem.html.
import nltk
from nltk.stem import PorterStemmer
porter = PorterStemmer()
Now to use these we need to apply them to each of the rows in our DataFrame. We could do this with a for loop, but again it’s more efficient to use the apply() method.
def stem_words(row):
stemmed_words = ''
for token in row.split(' '):
stemmed_words += porter.stem(token) + ' '
return stemmed_words
test_df = combined_novels_nyt_df[0:10]
test_df['pg_eng_text'] = test_df['pg_eng_text'].fillna('')
test_df['stemmed_text'] = test_df['pg_eng_text'].apply(stem_words)
You’ll notice I’m only doing this for the first 10 rows of the DataFrame, since this can be a time consuming process.
Now we can inspect the stemmed words. We can see what the first email looks like when it is stemmed:
print(test_df['stemmed_text'][0][0:500])
This should give us the following output:
the project gutenberg ebook of don quixote
thi ebook is for the use of anyon anywher in the unit state and
most other part of the world at no cost and with almost no restrictions
whatsoever. you may copi it, give it away or re-us it under the terms
of the project gutenberg licens includ with thi ebook or online
at www.gutenberg.org. if you are not locat in the unit states,
y will have to check the law of the countri where you are located
befor use thi ebook.
title: don quixote
And compare it to the original:
The Project Gutenberg eBook of Don Quixote
This ebook is for the use of anyone anywhere in the United States and
most other parts of the world at no cost and with almost no restrictions
whatsoever. You may copy it, give it away or re-use it under the terms
of the Project Gutenberg License included with this ebook or online
at www.gutenberg.org. If you are not located in the United States,
you will have to check the laws of the country where you are located
before using this eBook.
We notice that stemming lowercased the words, but it did not remove the punctuation. It also did not remove the stop words. We can tell it stemmed the words because united became unite, and states became state. If we had lemmatized instead of stemmed, we would have gotten the same result, since lemmatizing is a more complex process that requires a dictionary of words to reduce them to their base form. Eventually though we might have seen examples like are becoming be and located becoming locate.
Stop Words
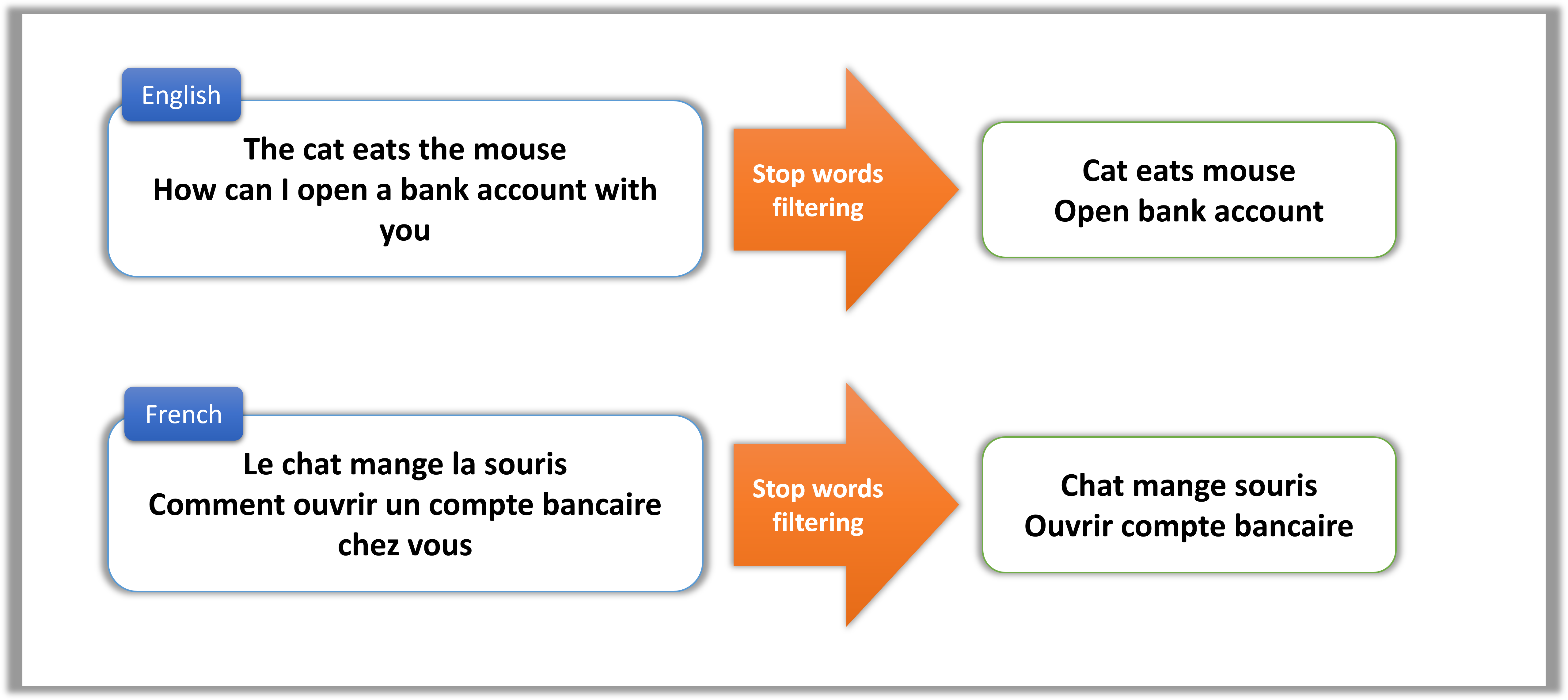
Stop words are a term for the most common words in a language, and they are often removed from text data because they do not contain much information. The term was coined by Hans Peter Luhn in 1958, when he was developing the concept of Keywords In Context (KWIC) indexing.

|

|
| Images from Luhn, H. P. “Key Word-in-Context Index for Technical Literature (Kwic Index).” American Documentation 11, no. 4 (1960): 288–95. https://doi.org/10.1002/asi.5090110403. | |
KWIC is part of information retrieval, and is a way of indexing text data that allows you to quickly find the context of a word in a document. It is a common way of indexing text data, and it is often used in search engines to quickly find the context of a word in a document.
Part of why stop words are so important for KWIC or just text analysis generally is that because we now know that the most common words will have a disproportionately high frequency in a text due to Zipf’s law, so if we don’t remove them then they overwhelm many methods for information retrieval or modeling.
For example, the words the, and, and of are some of the most common stop words in English. NLTK has a built-in list of stop words for many languages, which you can access using the nltk.corpus module. You can read more about the stop words in NLTK here https://www.nltk.org/book/ch02.html.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
print(stop_words)
Which would give us the following output:
then, more, so, ain, d, off, which, have, her, few, weren't, where, aren't, has, only, for, didn, was, from, our, further, haven't, in, doesn't, very, before, all, o, is, you, some, not, are, ll, won, through, nor, hadn't, than, again, too, hasn't, most, ours, other, shan't, why, shouldn, isn, wasn't, down, theirs, above, will, what, once, doing, hadn, am, my, hasn, such, herself, s, shan, been, your, if, at, below, that, she's, now, these, as, won't, whom, mightn, to, y, should've, any, ma, yourselves, each, that'll, yourself, being, ve, his, up, mightn't, you'd, did, do, haven, mustn't, wouldn, didn't, but, don't, mustn, you're, them, because, she, by, aren, over, weren, between, having, those, had, until, an, about, themselves, their, can, it's, against, re, how, and, couldn't, during, after, needn, or, doesn, wasn, we, a, just, should, you've, here, shouldn't, while, ourselves, hers, were, there, you'll, into, of, no, m, isn't, out, on, myself, me, with, needn't, him, it, he, same, himself, when, its, under, own, yours, itself, don, couldn, they, both, does, be, this, the, wouldn't, t, who, i
We can use this list to remove stop words from our text data.
def remove_stop_words(row):
return ' '.join([word for word in row.split(' ') if word not in stop_words])
test_df['stop_words_removed_text'] = test_df['pg_eng_text'].apply(remove_stop_words)
However, as much as this is a common step in text analysis, it is again an interpretative one. If you remember to the start of the course, we discussed how AI crawlers filter out content from the web based on the “List of Dirty, Naughty, Obscene, and Otherwise Bad Words” that you can find here https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words.
As we discussed, such a crude method often filters out materials from more marginalized communities, and in many ways stop words can potentially do the same if we are not careful.
One of the ways to avoid unintentionally filtering out this information is to actually inspect the stop words list and see if there are any words that you might want to keep. For example, in the NLTK stop words list, we see that not is a stop word, but in many cases it is a very important word for sentiment analysis. So we might want to remove it from the list of stop words.
stop_words.remove('not')
We can also create our own custom stop words list. For example, many digital humanists are working on projects to develop custom stop words lists for historic or under-resourced languages, since most commercially available lists are only for either the most popular languages or even more often only European languages.2 Before we go deeper though, we should start to explore some of the more advanced text analysis methods since that can help us determine some of these interpretative choices, which we will do in the next lesson.
-
If you want to learn more I would highly recommend taking a look at François Dominic Laramée, “Introduction to stylometry with Python,” Programming Historian 7 (2018), https://doi.org/10.46430/phen0078. Stylometry is the formal name for this type of analysis and it is a both a popular method for working with cultural data and one with a longer history. For example, in the 1960s the authorship of the Federalist Papers was determined using stylometry. ↩
-
Burns, Patrick J. “Constructing Stoplists for Historical Languages.” Digital Classics Online, December 5, 2018, 4–20. https://doi.org/10.11588/dco.2018.2.52124. ↩