Introduction to File Formats & Text
Now that we have seen how we can use the command line to create directories and files, and move them around. It seems like we’re doing a lot of work to do something that we could do with a GUI, but the command line is actually much more powerful than a GUI. For example, we can use the command line to do things like search for text in a file, count the number of words in a file, and even delete a file.
Before we try that though, let’s learn a bit more about what files are exactly.
Introducing File Formats
What constitutes a document or a file might seem obvious, but is actually a robust and ongoing scholarly debate in Library and Information Sciences (LIS) and Computer Science (CS). To put it a bit simply, a file is a collection of data stored in a single unit, identified by a filename. It can be a document, an image, a video, a sound, or any other collection of data. The file extension is the part of the file name after the period. The file extension tells the computer what type of file it is and what program to use to open it.

There are many different file formats and each one has its own purpose. For example, a .docx file is a Microsoft Word document, a .jpg file is an image, and a .mp3 file is an audio file. Some file formats are proprietary, meaning they are owned by a company and can only be opened by certain programs. For example, .docx files can only be opened by Microsoft Word. So if you try to open up a word document in a PDF Viewer you might see what looks like a bunch of gibberish.
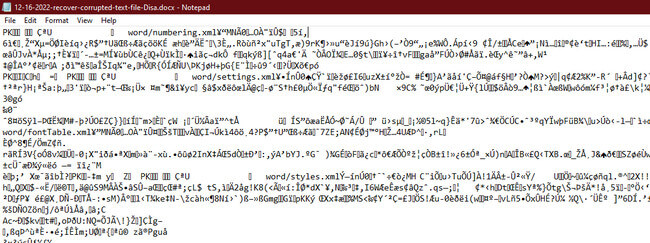
This gibberish is actually the code that makes up the file, but since the PDF Viewer doesn’t know how to read the code it just shows you the code itself rather than the data stored in the files.
Other file formats are open source, meaning they are not owned by a company and can be opened by many different programs. For example, .txt files are plain text files that can be opened by any text editor. When we used the touch command, we told the terminal to create a .txt file. This is because .txt files are the simplest file format and only contain text. They do not contain any formatting like bold, italics, or images.
What is Plain Text?
Today, we have been talking a lot about text, from text commands to text files. But the core concept with both of these is the idea of plain text.
As scholars working with computers, we need to be aware of the ways plain text and formatted text differ. While a Word Document ant .txt file might look the same to us, the Word Document actually contains a lot of hidden formatting that the .txt file does not. In programming, we want to be explicit in our communications with computers and so plain text is preferable, but what is it exactly?
According to the Unicode Standard,
Plain text is a pure sequence of character codes; plain Unicode-encoded text is therefore a sequence of Unicode character codes.
This is a bit technical, but the key concept is that plain text shows if it is formatted or not (we call this markup), and usually contains no formatting. Plain text can be moved between programs more fluidly and can respond to programmatic manipulations. It is often manipulated in something called a text editor (like VS Code), which is a program that allows you to edit plain text files.
We can see an example of a plain txt file, via Project Gutenberg - a website that hosts public domain books in plain text format.
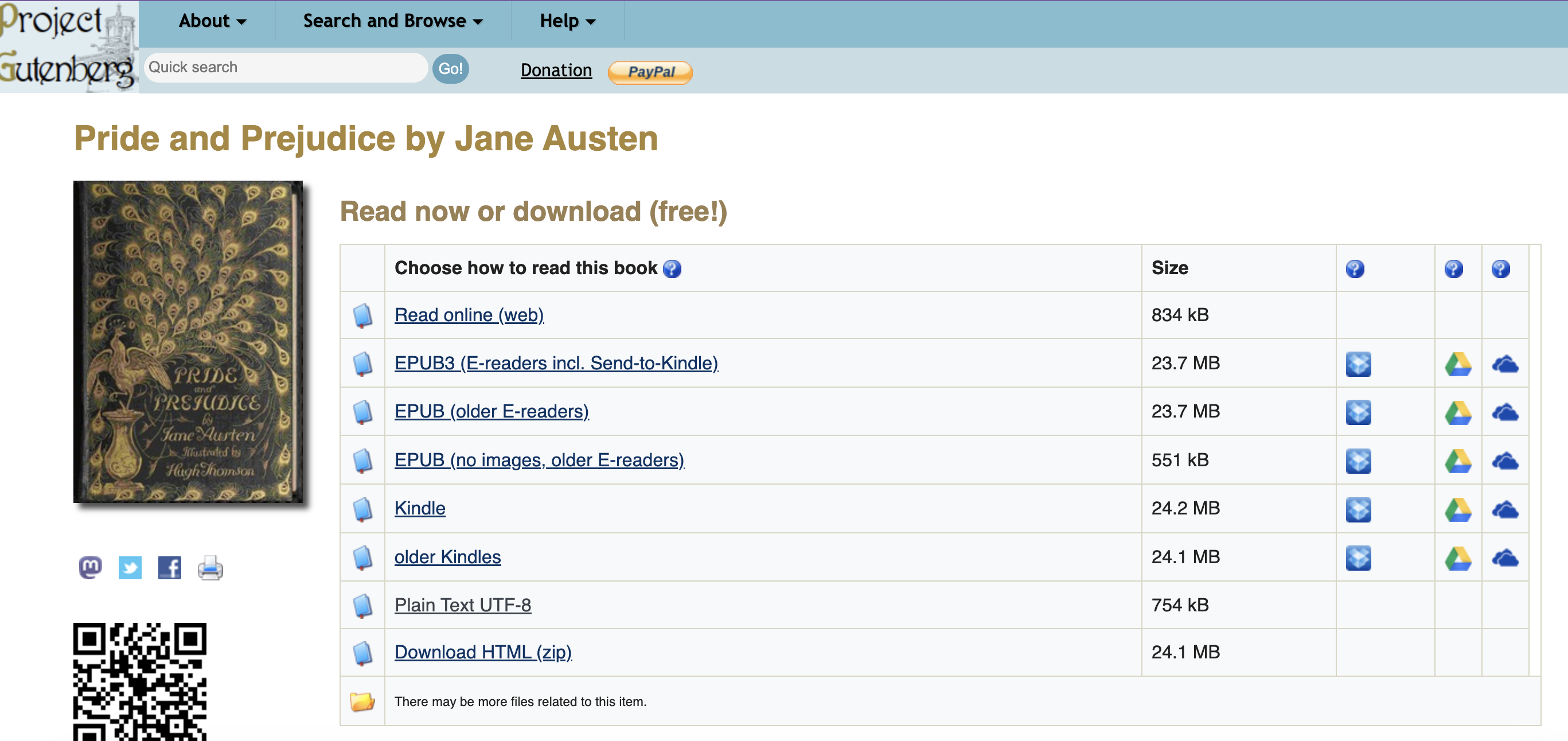
I can download this file directly from my terminal using the command line:
curl https://www.gutenberg.org/files/1342/1342-0.txt > pride-and-prejudice.txt
In this example, I’m using the command curl to download the file from the internet. The > symbol tells the terminal to create a new file, store this data in the file, and save the file as pride-and-prejudice.txt. We can see that this file is a .txt file, meaning it is a plain text file. curl stands for “client URL” and is a command line tool for transferring data and downloading files from the internet. We can also use it to upload files to the internet.
If you are on a Windows computer, you can instead use the command wget to download the file from the internet. The syntax is the same, but the command is different.
wget https://www.gutenberg.org/files/1342/1342-0.txt > pride-and-prejudice.txt
wget stands for “web get” and is a similar command line tool for retrieving and downloading files from the web.
If you are using PowerShell and not WSL (again WSL is recommended!), the command looks slightly different:
wget https://www.gutenberg.org/files/1342/1342-0.txt -OutFile pride-and-prejudice.txt
Now that we have downloaded this file, we can use the command line to display some of the text:
cat pride-and-prejudice.txt
cat stands for concatenate, and is a command line tool for displaying the contents of a file. We can see that this file contains the text of Pride and Prejudice by Jane Austen (though you’ll likely only see the end of the text since it is so long, without scrolling for ages).
We can start to interact with this file in a number of ways.
First, let’s count how many words are in this file. To do this, we can use the command wc -w. Let’s try it out!
wc -w pride-and-prejudice.txt
wc stands for word count, and the -w flag tells the terminal to count the number of words in the file. You’ll often notice that commands have flags like this, which are additional instructions for the command.
We can also use the command wc to count the number of lines in a file with the -l flag. Let’s try it out!
wc -l pride-and-prejudice.txt
We should see that there are 14911 lines in this file.
We can also search for a specific word in a file using the command grep. Let’s try to find out how often the word “pride” appears in this file. To do this, we can use the command grep pride pride-and-prejudice.txt. Let’s try it out!
grep pride pride-and-prejudice.txt
This should give us the following output:
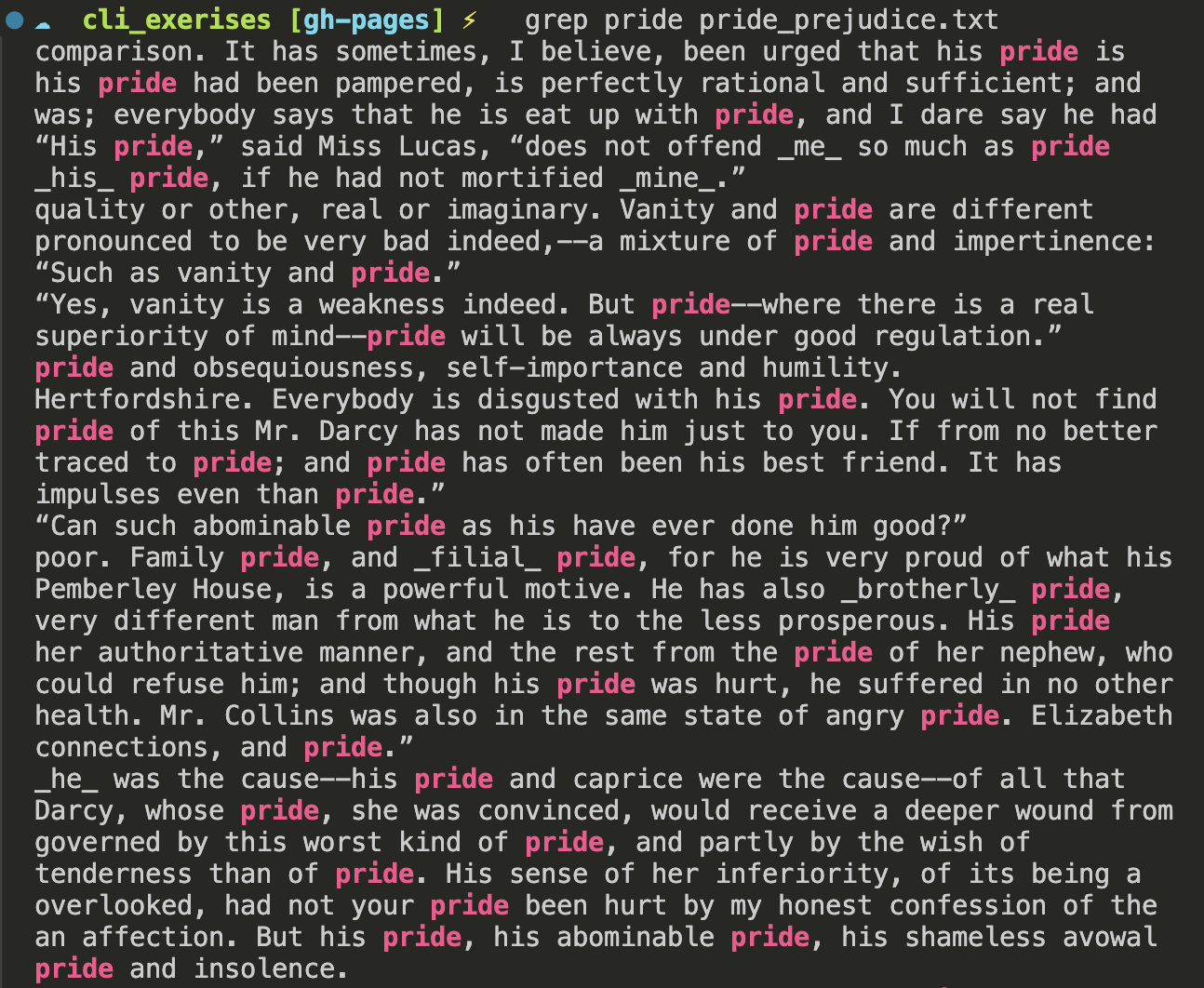
How could we count the number of times the word “pride” appears in this file? We could use the command wc -w to count the number of words, but that would include the word “pride” in the title of the book. We could also use the command wc -l to count the number of lines, but that would include the line numbers. Instead, we can use the command grep -c pride pride-and-prejudice.txt.
We can see that the word “pride” appears 43 times in this file. How many times does the word “prejudice” appear?
Introducing Markdown
While .txt files are useful, in digital humanities we often use a file format called Markdown. Like txt, Markdown is a plain text file format that uses symbols to add formatting to the text, and has the file extension .md. You have already seen an example of this with the README.md files on GitHub.
Let’s try creating a Markdown file in our folder. We can do this by using the touch command and adding .md to the end of the file name.
touch is310-computing-humanities.md
Now we can open this file in VS Code and add some text to it.
Computing in the Humanities is defined as the application of computational methods and tools to the study of humanistic questions.
Now if we wanted too, we could add some formatting to this text using Markdown.
Maybe we want to highlight the word “Computing in the Humanities” in bold. To do this we would put two asterisks on either side of the word.
**Computing in the Humanities** is defined as ...
We could also put defined into italics by putting one asterisk on either side of the word.
**Computing in the Humanities** is *defined* as ...
Finally, we could add a heading to this text by putting a hashtag in front of the heading.
# Welcome to Computing in the Humanities
We can see what this looks like in VS Code by using the Markdown Preview extension. To do this, click on the icon in the top right corner of VS Code that looks like a magnifying glass. This will open a preview of the Markdown file in a new tab.
You should see something like this, where our Markdown file is on the left and the preview is on the right:

Now you can see that our formatting has been applied to the text. This type of formatting is called Markdown syntax and it is a way of adding formatting to plain text files. What we did was exactly the same as what you do when you use the buttons in Word or Google Docs to add headers or styling to your text. The difference is that we are using symbols to add this formatting instead of buttons.
This may seem like a lot of extra work, but the advantages of Markdown are numerous.
- It is much more sustainable than Word or Google Docs. This is because the text is saved as plain text and not in a format that is optimized for editing. This makes it future-proof so that you don’t require a license or access to an application to see your files.
- It can also be rendered by any text editor. This is because Markdown is a plain text format and not a rich text format. This makes it platform agnostic.
- Finally, Markdown plays nicely with Github, which renders it directly in your browser. This makes it easy to push up your files into your repositories.
Markdown was created by John Gruber with help from Aaron Swartz in 2004. The goal was to create a file format that was easy to read and write, could be converted into web documents, and could be used by anyone. You can read more about the history of Markdown, in Bednarski, Dawid. “The History of Markdown: A Prelude to the No-Code Movement.” Taskade Blog, March 25, 2022. https://www.taskade.com/blog/markdown-history/.
It’s important to understand that Markdown has this history because many flavors of Markdown exist, and standardization of Markdown has been an ongoing project. For example, GitHub Flavored Markdown (GFM) is a flavor of Markdown that was created by GitHub in 2009. It is a superset of Markdown, meaning it adds additional features to Markdown. For example, GFM allows you to create tables in Markdown, which is not possible in regular Markdown. You can read more about GFM in “GitHub Flavored Markdown Spec.” GitHub, 2022. https://github.github.com/gfm/.

This figure shows some examples of how Markdown is written depending on the platform and standards. You can also see some of the discussions that go on to help shape these standards through the various repositories on GitHub that host the standards. For example, CommonMark is another popular Markdown style and improvements to it are discussed in this repository https://github.com/commonmark/commonmark-spec/issues.
First Exercise
Now that you have a basic understanding of Markdown, let’s try improving the README.md file in our is310-coding-assignments repository. To do this, we are going to use the Markdown Preview extension in VS Code.
Try adding the following elements:
- A heading
- A subheading
- A bulleted list
Bonus option:
- A Link to our course website
You can use both AI tools and this GitHub Markdown Cheatsheet to help you. Once you’ve completed the exercise, push up your changes to GitHub.
Homework: Lost & Found in the Command Line

Part 1: Build a Command Line Corn Maze
The Fall weather is officially here, which means it is time to get lost in a corn maze! But since we are in the digital humanities, we are going to get lost in a command line maze instead.
For this assignment, you will be using your new mastery of the command line to create a maze for your classmates to solve. You should work individually on this, though you are welcome to brainstorm ideas.
First, you should create a new folder in your is310-coding-assignments repository called command-line-maze. Inside this folder, you should create a maze using directories and files.
Your maze should have the following components:
- An entrance and a solution
- At least 5 directories (these can be nested)
- At least 5 files (these can be nested)
- One hidden file or directory
- Clues to help us solve the maze
You are welcome to use Project Gutenberg https://www.gutenberg.org/ for your files, but you can also use other files if you prefer. You can also use the command line to create your files, but you can also use a text editor if you prefer.
You also need to include a README.md file in your maze folder that provides any relevant instructions for solving the maze. This could include a list of commands that we should use to solve the maze, or any other information that you think would be helpful. Be sure to include a header at the top of the file that lists the name of the maze and your name.
Once you have created your maze, you should zip the folder that contains your maze. If you do not know how to zip a file, you can usually right click on the file and select “Compress” or “Zip”. If you are using the command line, you can use the command zip -r path/to/your/zip/file path/to/your/directory to zip the file. Be sure to replace these dummy file paths with your actual desired ones (or ask AI for help!).
Be sure to not zip the README.md file, as we will need to read this file to solve the maze. Once you have zipped your maze, you should upload it to your is310-coding-assignments repository and post a link in our GitHub discussion https://github.com/cultureasdata-uiuc/is310-fall-2024/discussions/2.
If you need inspiration for your maze, take a look at this one I created, which you can download as a zip file or via our GitHub repository (you can also try solving it if you like!).
Part 2: Solve the Command Line Corn Maze
Once you have created and zipped your maze, pushed it up to GitHub, and posted a link in our discussion, it’s time to try and solve someone else’s maze.
The first step is to select one of your peers’ mazes from the discussion link and try cloning their repository to your computer. Remember if you have setup SSH keys, you can use the SSH link, otherwise you can use the HTTPS link.
git clone name-of-repo
Once you have cloned the repository, you should use the command line to enter the maze folder. If you are having issues with cloning, you can also download the zip file and unzip it on your computer. But I would recommend trying to clone the repository first, since it is a very useful skill to have and one you will often need as a coder.
To enter the cloned repository, you can do this by using the cd command to navigate to the maze folder. You can read the README.md file to get any relevant instructions for solving the maze. To print out the contents of the file, you can use the cat command.
cat README.md
Once you are in the maze folder and have read the instructions, you should unzip the maze.
For Unix/Linux (so Macs, Linux, and the Window Subsystems for Linux), you can use the following command:
unzip path/to/your/zip/file -d path/to/your/desired/directory
The -d flag is just telling the terminal where to unzip the file. So if you are already in the correct spot, you can just use unzip path/to/your/zip/file.
If you are using PowerShell, you will need to use the following command:
Expand-Archive -Path "path\to\your\zip\file" -DestinationPath "path\to\your\desired\directory"
Again the -DestinationPath flag is just telling the terminal where to unzip the file. So if you are already in the correct spot, you can just use Expand-Archive -Path "path\to\your\zip\file".
Be sure to replace these dummy file paths with your actual desired ones (or ask AI for help!). Your goal with this maze is to use both the command line cheatsheet and your preferred AI chatbot to solve the maze. You should be able to solve the maze in ~30 minutes, but if you are struggling, please reach out to the instructors via Slack for help.
You should use the cd command to navigate through the maze and the ls command to see what is in each directory, or ls -la if you think there might be hidden materials. You can also use the cat command to read the contents of files.
Once you have solved the maze, you should reply to their post in the discussion, letting them know that you were successful and posting a screenshot of your solved maze in your terminal. If you have any issues with the maze, you’re welcome to request help on their post, but please try to solve it on your own first.
I would encourage you to try and solve a maze that has not been solved yet, but if you are struggling, you can try solving one that has already been solved. You can also try solving multiple mazes if you like.
Additional Resources
In addition to the resources, I linked at the beginning of this lesson, I would recommend the following:
- Ian Milligan and James Baker, “Introduction to the Bash Command Line,” The Programming Historian 3 (2014), https://programminghistorian.org/en/lessons/intro-to-bash. This is an introduction to the Bash shell, which will serve well enough as an introduction to other shells like Zsh as well.
- Bash Basics Part 1 of 8 Access and Navigation
- Beginner’s Guide to the Bash Terminal
- The Most Important Thing You’ll Learn in the Command Line
- Go through the CodeAcademy command line course.
- Shell Scripting Tutorial