Exploring Computational Methods for Cultural Data
Advanced Text Analysis Exploration
Now that you are starting to learn the basics of text analysis, you can start to explore more advanced techniques that you might want to use in your final project. Today I will be sharing code to help you get started with some information extraction, using Named Entity Recognition (NER), and information retrieval, using Term Frequency-Inverse Document Frequency (TF-IDF). These methods are just some of the possible ones you might want to use, and I list additional options below.
Cleaning Project Gutenberg Texts
Before we can start trying them out though, one issue we haven’t addressed is the fact that each Project Gutenberg book has a header and footer that we might want to remove before we start our analysis. This is a common issue with text data, and it is often called “noise” in the data. We could use regular expressions to remove this data, but there’s also existing Python libraries for working with Project Gutenberg data. In particular, the gutenbergpy library has functionality to remove that metadata. You can find information about the library here https://github.com/raduangelescu/gutenbergpy and install it with the following command:
pip install gutenbergpy
This library has a set of text markers that it uses to remove the headers and footers that you can see here https://github.com/raduangelescu/gutenbergpy/blob/master/gutenbergpy/textget.py#L23 and in this figure:
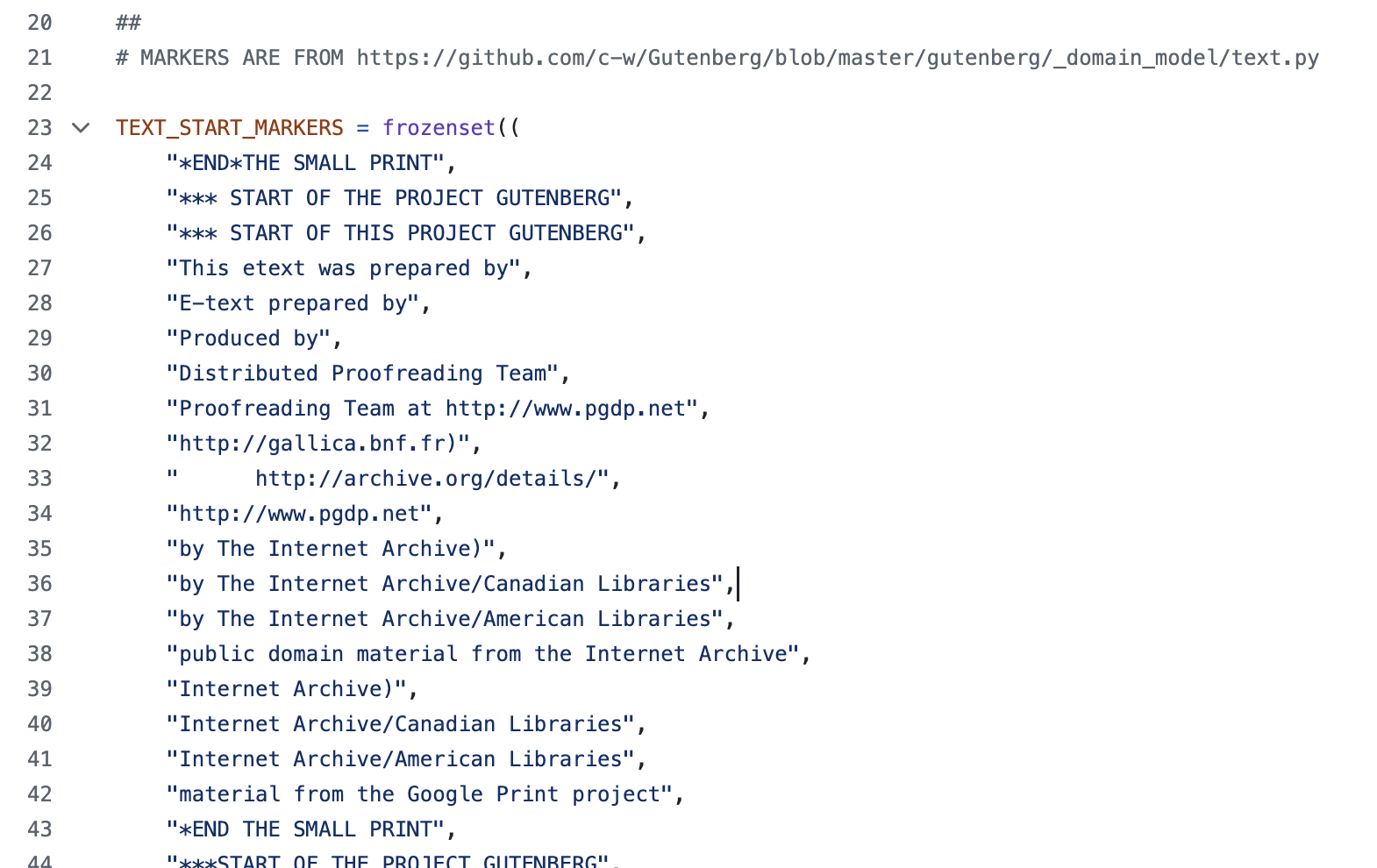
To use the library, you can use the following code:
import gutenbergpy.textget
def clean_book(url):
# This gets a book by its gutenberg id number
if pd.notna(url):
pg_id = url.split('/pg')[-1].split('.')[0]
try:
raw_book = gutenbergpy.textget.get_text_by_id(pg_id) # with headers
clean_book = gutenbergpy.textget.strip_headers(raw_book) # without headers
return clean_book
except Exception as e:
print(f"Error getting book: {e} with id: {pg_id} and url: {url}")
return None
tqdm.pandas(desc="Cleaning Books")
combined_novels_nyt_df['cleaned_pg_eng_text'] = combined_novels_nyt_df.progress_apply(clean_book, axis=1)
This code will get the text of the book by its Project Gutenberg ID, which we are deriving from the Gutenberg URL, and then remove the headers and footers. Such a step is necessary since otherwise the headers and footers would be included in our text analysis, which would skew our results.
Information Extraction Methods
Now that we have our cleaned data, we can start to explore some information extraction methods. We cannot cover them all in this course but I wanted to share some common approaches and Python Libraries that you might want to explore further.
Methods for textual data:
- Part of Speech Tagging: This is a technique that assigns parts of speech to each word in a sentence. For example, it might tag a word as a noun, verb, adjective, etc. This can be useful for identifying the grammatical structure of a sentence.
- Dependency Parsing: This is a technique that assigns syntactic structure to a sentence. For example, it might identify the subject, object, and verb in a sentence. This can be useful for understanding the relationships between words in a sentence.
- Coreference Resolution: This is a technique that identifies when two or more words in a sentence refer to the same entity. For example, it might identify that “he” and “John” refer to the same person. This can be useful for understanding the relationships between entities in a text.
Popular Python libraries for these tasks include:
- spaCy library https://spacy.io/: spaCy is a popular Python library for NLP that provides a wide range of tools for information extraction, including Named Entity Recognition (NER), Part of Speech Tagging, Dependency Parsing, and Coreference Resolution. spaCy is known for its powerful architecture and multiple models for different languages. Here’s an example of a dependency parse tree from spaCy:

- Stanford CoreNLP https://stanfordnlp.github.io/CoreNLP/: Stanford CoreNLP is a suite of tools for NLP that provides a wide range of tools for information extraction, including Named Entity Recognition (NER), Part of Speech Tagging, Dependency Parsing, and Coreference Resolution. Stanford CoreNLP is an older library but is still widely used for these tasks.
- Riveter NLP https://github.com/maartensap/riveter-nlp is a Python package that measures social dynamics between personas mentioned in a collection of texts. The package identifies and extracts the subjects, verbs, and direct objects in texts; it performs coreference resolution on the personas mentioned in the texts.
- The Classical Language Toolkit https://github.com/cltk/cltk is a Python library that provides NLP tools for classical languages. The library includes tools for tokenization, lemmatization, part-of-speech tagging, and named entity recognition for classical languages like Latin and Greek.
- BookNLP https://github.com/dbamman/book-nlp is a Python library that provides NLP tools for analyzing novels. The library includes tools for tokenization, lemmatization, part-of-speech tagging, and named entity recognition for novels.
Methods for image or video data:
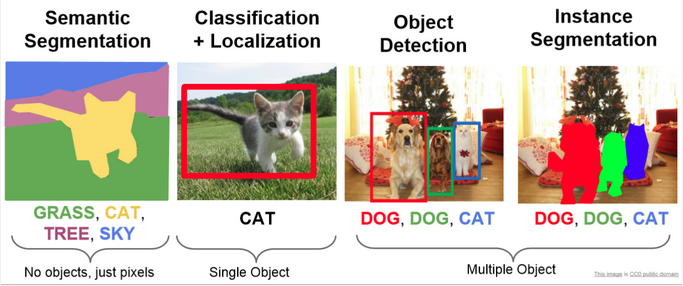
- Object Detection: This is a technique that identifies objects in an image or video. For example, it might identify a person, car, or tree in an image. This can be useful for understanding the content of an image or video, and in many ways is similar to NER, which we will explore more in-depth below.
- Facial Recognition: This technique is a subset of Object Detection that identifies faces in an image or video. For example, it might identify a person’s face in an image. It is usually discussed as a separate category from Object Detection because it is a specialized form of Object Detection, and because of the deeply problematic ethical implications of facial recognition technology.
- Optical Character Recognition (OCR): We have discussed this technique in-depth, but never as an information extraction technique, even though that is technically what it is doing, as we can see in this figure:

- Edge Detection: This is a technique that identifies edges in an image or video. For example, it might identify the edges of a person, car, or tree in an image. This can be useful for understanding the content of an image or video, and for tasks like image classification and object detection.
- Image Segmentation: This is a technique that identifies regions in an image or video. It is similar to object detection, but it identifies regions instead of objects. This can be useful for understanding the content of an image or video, and for tasks like image classification and object detection.
Popular Python libraries for these tasks include:
- OpenCV https://opencv.org/: OpenCV is a popular Python library for computer vision that provides a wide range of tools for image and video analysis, including object detection, facial recognition, and image segmentation. OpenCV is known for its speed and accuracy and is widely used in industry and academia.
- TensorFlow https://www.tensorflow.org/: TensorFlow is a popular Python library for machine learning that provides a wide range of tools for image and video analysis, including object detection, facial recognition, and image segmentation. TensorFlow is known for its flexibility and is widely used in industry and academia.
- PyTorch https://pytorch.org/: PyTorch is a popular Python library for machine learning that provides a wide range of tools for image and video analysis, including object detection, facial recognition, and image segmentation. PyTorch is known for its flexibility and is widely used in industry and academia.
- Dlib http://dlib.net/: Dlib is a popular Python library for computer vision that provides a wide range of tools for image and video analysis, including object detection, facial recognition, and image segmentation. Dlib is known for its speed and accuracy and is widely used in industry and academia.
- Scikit-Image https://scikit-image.org/: Scikit-Image is a popular Python library for image processing that provides a wide range of tools for image and video analysis, including object detection, facial recognition, and image segmentation. Scikit-Image is known for its speed and accuracy and is widely used in industry and academia.
- Distant Viewing Toolkit https://distantviewing.org/: The Distant Viewing Toolkit is a Python library that provides tools for analyzing images and videos. The library includes tools for object detection, facial recognition, and image segmentation, and is specifically designed for digital humanities research.
Named Entity Recognition (NER) & SpaCy
What is Named Entity Recognition?
From the Wikipedia article:
“Named-entity recognition (NER) (also known as (named) entity identification, entity chunking, and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.”
What does this look like in practice? Let’s look at a few examples.

We can see that in these images, parts of the text are being highlighted and classified as different categories (or entities if you will). Many of these examples might seem straightforward, but how do we decide what is an entity exactly? And how did NER become a defined field instead of just being part of text mining?
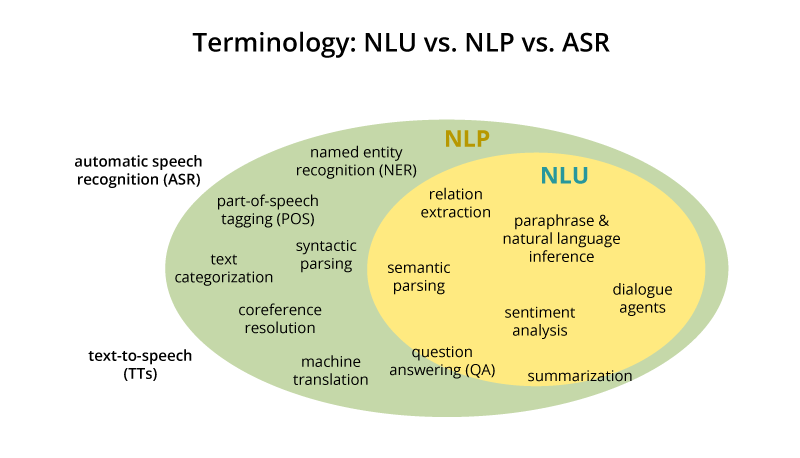
This graph represents a common typology of NLP tasks, comparing it to Natural Language Understanding and Automatic Speech Recognition.
While technically correct, I find this graph confusing 🤔. The exact definition of NER’s boundaries relative to other nlp/nlu tasks is very porous. For example, in addition to recognizing entities, NER can also include parts of text classification, entity disambiguation, relationship extraction all parts of NER (though they are separated in this chart).
So if this is so porous how did NER first develop?
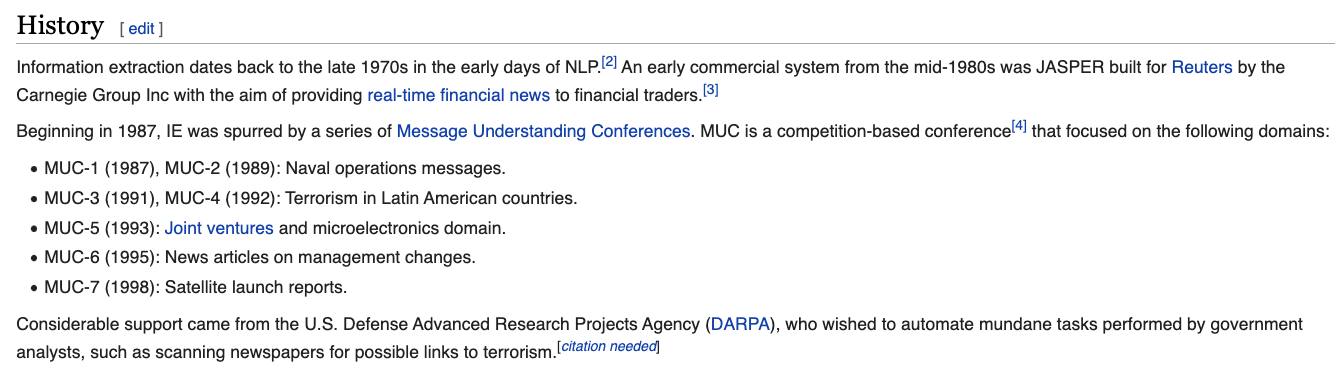
From this Wiki page, we can see that the concept of “named entity” first developed at the Message Understanding Conference-6 in 1995. Here’s an example template given to participants from MUC-3 and you can even read the original MUC manual here https://www-nlpir.nist.gov/related_projects/muc/muc_sw/muc_sw_manual.html:

The big takeaway is that NER is relatively new. The field really takes off as a field with Text Analysis Conferences beginning in 2009 https://tac.nist.gov/ and it is also relatively recent in digital humanities.
The first DH conference presentation listing NER as a topic was in 2004:

Information Retrieval Methods
Now that we are seeing how information extraction can help us augment and understand our textual data, we can start to explore information retrieval methods. It is important to note that the line between information extraction and retrieval can be blurry, but in general, information extraction is about extracting structured information from unstructured text, while information retrieval is about retrieving relevant information from a collection of documents.
Methods for textual data:
- Topic Modeling is a technique that identifies topics in a corpus of text data. Topic modeling works by identifying groups of words that frequently appear together in the corpus and assigning them to topics. Each topic is a group of words that are related to each other, and each document in the corpus is assigned a distribution over the topics. There are many different implementations of topic modeling, including Latent Semantic Allocation (LSA), Latent Dirichlet Allocation (LDA), and Non-negative Matrix Factorization (NMF).
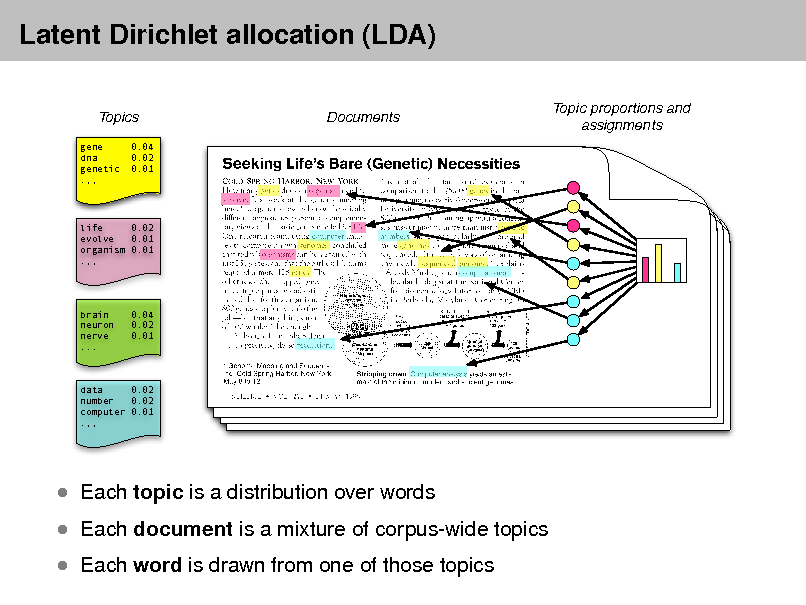
- Word Embeddings is a technique that represents words as vectors in a high-dimensional space. Word embeddings are useful for capturing the semantic relationships between words in a corpus of text data. There are many different implementations of word embeddings, including Word2Vec, GloVe, and FastText.
- Contextual Embeddings is a technique that represents words as vectors in a high-dimensional space, taking into account the context in which the words appear. Contextual embeddings are useful for capturing the semantic relationships between words in a corpus of text data. There are many different implementations of contextual embeddings, including BERT, GPT-2, and XLNet.
- Document Similarity & Ranking is a suite of techniques including Cosine Similarity, Jaccard Similarity, and BM25 that are used to measure the similarity between documents in a corpus of text data. Document similarity and ranking are useful for identifying similar documents in a corpus and for ranking documents based on their relevance to a query.
Popular Python libraries for these tasks include:
- Gensim https://radimrehurek.com/gensim/: Gensim is a popular Python library for topic modeling and word embeddings. Gensim provides a wide range of tools for analyzing text data, including LDA, Word2Vec, and Doc2Vec.
- FastText https://fasttext.cc/: FastText is a popular Python library for word embeddings. FastText provides a wide range of tools for analyzing text data, including word embeddings and text classification.
- BERT https://huggingface.co/transformers/model_doc/bert.html: BERT is a popular Python library for contextual embeddings. BERT provides a wide range of tools for analyzing text data, including contextual embeddings and text classification.
- Scikit-Learn https://scikit-learn.org/: Scikit-Learn is a popular Python library for document similarity and ranking. Scikit-Learn provides a wide range of tools for analyzing text data, including cosine similarity, Jaccard similarity, and BM25.
- Transformers https://huggingface.co/transformers/: Transformers is a popular Python library for contextual embeddings. Transformers provides a wide range of tools for analyzing text data, including BERT, GPT-2, and XLNet.
Methods for image or video data:
- Image Classification is a technique that assigns labels to images based on their content. For example, it might classify an image as a cat, dog, or car. Image classification is useful for understanding the content of images and for tasks like object detection and image segmentation.
- Image Clustering is a technique that groups similar images together based on their content. For example, it might group images of cats together and images of dogs together. Image clustering is useful for organizing large collections of images and for tasks like image retrieval and image recommendation.
- Image Similarity & Ranking is a suite of techniques including Cosine Similarity, Jaccard Similarity, and Euclidean Distance that are used to measure the similarity between images. Image similarity and ranking are useful for identifying similar images in a collection and for ranking images based on their relevance to a query.
Popular Python libraries for these tasks include:
- Many of the same libraries used for textual data analysis can also be used for image and video data analysis, including OpenCV, TensorFlow, PyTorch, and Scikit-Image. These libraries provide a wide range of tools for analyzing image and video data, including object detection, facial recognition, and image segmentation.
TF-IDF & Scikit-Learn
Term Frequency - Inverse Document Frequency or TF-IDF was first proposed in a 1972 paper by Karen Spärck Jones under the name “term specificity” and was later named TF-IDF by Steve Robertson in 1976. The algorithm is used to determine the importance of a word in a document relative to a collection of documents. The algorithm is based on the idea that a word is important if it appears frequently in a document, but infrequently in the rest of the documents in the collection.
The reason TF-IDF is so popular is because it is intended to surface terms that are distinctive across as set of documents (or a corpus). Often times with word counting you get lots of high frequency words (remember Zipf’s law) but these words aren’t always helpful if you are trying to understand the concepts within the text. High frequency words are more useful for author attribution.
So the way TF-IDF works is the following operations as visualized in this diagram:

To break this down into code it really looks like the following:
term_frequency = number of times a given term appears in document
inverse_document_frequency = log(total number of documents / number of documents with term) + 1*****
tf-idf = term_frequency * inverse_document_frequency
Advanced Computational Methods
In addition to information extraction and retrieval, general modeling techniques allow us to explore and classify patterns in data. These methods are widely applicable across text, image, and network data, providing diverse ways to interpret and model cultural information.
Network Analysis
Network analysis examines relationships between entities, such as characters in novels, authors and their works, or people and organizations in historical documents. By representing entities as nodes and relationships as edges, network analysis allows us to model complex interactions.
- Graph Creation: Network models can be constructed using libraries like NetworkX or iGraph for Python. These libraries allow for flexible creation of graphs, from basic connections to complex, weighted, or directed graphs.
- Centrality Measures: Metrics like degree, betweenness, and closeness centrality help identify influential nodes in a network. For example, in a network of historical figures, centrality measures might reveal key connectors or influencers within cultural or social movements.
- Community Detection: Techniques like modularity-based clustering and Louvain algorithm identify sub-groups or communities within a network. Community detection can be valuable in studying thematic clusters or social groups in cultural datasets.
- Visualization: Network visualizations can reveal patterns that are hard to identify in raw data. Gephi, Cytoscape, and PyVis are popular tools for visually exploring networks.
Classification Models
Classification models can assign labels to data based on learned patterns. These models are particularly useful for categorizing documents, images, or entities into predefined categories.
- Random Forests: A Random Forest is an ensemble learning method based on decision trees. It’s known for robustness and interpretability and can be used for tasks like author classification, genre prediction, or sentiment analysis. Random forests aggregate predictions from multiple trees, reducing overfitting and improving accuracy.
- Support Vector Machines (SVMs): SVMs are effective for high-dimensional text classification tasks, such as categorizing articles into topics. SVMs work by finding a hyperplane that best separates classes, making them particularly useful for binary classification tasks.
- Logistic Regression: Logistic regression, despite its name, is a classification method. It’s simpler than other models but often surprisingly effective, especially when interpretability is essential. It’s commonly used in social science and humanities research for binary and multi-class classification tasks.
- Neural Networks and Deep Learning: When working with large datasets or complex data (like images or text embeddings), neural networks offer powerful modeling options. Convolutional Neural Networks (CNNs) are particularly effective for image classification, while Recurrent Neural Networks (RNNs) and Transformers (e.g., BERT) are common for text classification and sequence prediction tasks.
Clustering Techniques
Clustering methods group similar data points, allowing us to explore underlying structures or themes without predefined categories. These methods are useful for exploratory data analysis in unsupervised learning contexts.
- K-Means Clustering: This is a popular clustering technique that partitions data into a predetermined number of clusters. In cultural datasets, k-means can group documents with similar themes or identify similar objects in image datasets.
- Hierarchical Clustering: Hierarchical clustering creates a dendrogram representing nested groupings within the data. This technique is valuable for visualizing how data points relate hierarchically, which can be insightful when studying genre similarities or character connections.
- Gaussian Mixture Models (GMMs): Unlike k-means, which assigns each data point to a single cluster, GMMs can model data as a mixture of multiple distributions. This flexibility is useful when dealing with overlapping cultural themes or nuanced data patterns.
Dimensionality Reduction
Dimensionality reduction techniques simplify data, making it easier to visualize and analyze high-dimensional datasets like word embeddings or image features.
- Principal Component Analysis (PCA): PCA reduces dimensionality by transforming data into principal components that explain the most variance. It is often used to preprocess data for clustering or classification and can also help visualize word embeddings.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is especially useful for visualizing high-dimensional data by projecting it onto a 2D or 3D plane. It’s commonly used to visualize clusters in embeddings from text or image data.
Time Series & Forecasting Analysis
When working with temporal data, such as publication dates or historical events, time series analysis can reveal trends and patterns over time.
- Trend Analysis: Techniques like moving averages and decomposition can help identify trends and seasonality in cultural datasets. For example, examining word usage trends over time can offer insights into shifting themes or sentiment.
- Autoregressive Integrated Moving Average (ARIMA): ARIMA models can forecast future trends based on past values. This is useful in historical studies or predicting trends in cultural data, such as publication or social media trends.
Tools and Libraries
For implementing these techniques, consider these widely used libraries:
- Scikit-Learn: Provides accessible implementations for classification, clustering, and dimensionality reduction. Scikit-Learn is a versatile tool for general modeling tasks and supports a range of classifiers like Random Forests, SVMs, and k-means.
- Statsmodels: Ideal for statistical modeling, including time series analysis.
- TensorFlow and PyTorch: Powerful libraries for building neural networks and deep learning models, especially for tasks involving large, complex datasets.
- NetworkX and Gephi: Useful for network analysis, providing tools for constructing, analyzing, and visualizing complex networks.
Each of these libraries has its own history, and some of what they provide overlaps. Here’s a helpful chart outlining some of their pros and cons.
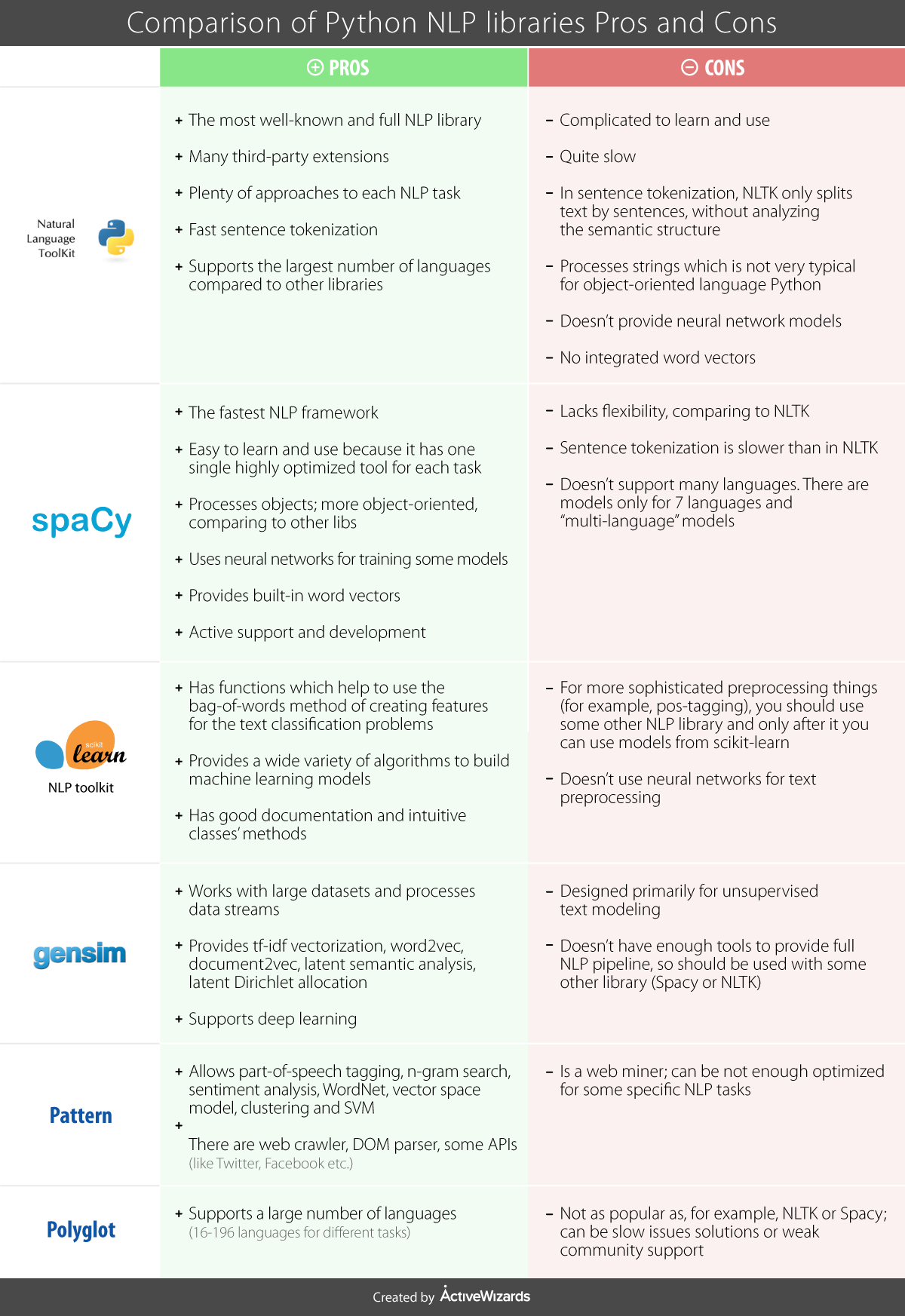
Ultimately, which library you choose to use depends on what you want to do with your data, but there’s some general principles for text analysis that you should consider regardless of method.
Resources
We have only briefly touched on the possibilities of text analysis in this lesson. There are many more techniques and algorithms that you can use to explore cultural data. Please be sure to take a look at the list of resources in the Computing Cultural Data assignment for more information (available here).
Peer Reviewed Tutorials
This list is not exhaustive and I would highly recommend taking a look at other resources that have been shared throughout the semester.
- Thomas Jurczyk, “Clustering with Scikit-Learn in Python,” Programming Historian 10 (2021), https://doi.org/10.46430/phen0094.
- Matthew J. Lavin, “Regression Analysis with Scikit-Learn (part 1 - Linear),” Programming Historian 11 (2022), https://doi.org/10.46430/phen0099.
- Matthew J. Lavin, “Regression Analysis with Scikit-Learn (part 2 - Logistic),” Programming Historian 11 (2022), https://doi.org/10.46430/phen0100.
- John R. Ladd, “Understanding and Using Common Similarity Measures for Text Analysis,” Programming Historian 9 (2020), https://doi.org/10.46430/phen0089.
- Matthew J. Lavin, “Analyzing Documents with TF-IDF,” Programming Historian 8 (2019), https://doi.org/10.46430/phen0082.
Peer Reviewed Papers
This list is not exhaustive and is primarily drawn from my graduate course, Culture At Scale (which you can see the syllabi here, Spring 2024 and Spring 2023). I’ve only included articles that have publicly accessible code and their order is random. Some of these articles are quite dense, so you should ask both the instructors and AI tools for help with the sections you don’t understand.
- Kleymann, Rabea, Andreas Niekler, and Manuel Burghardt. “Conceptual Forays: A Corpus-Based Study of ‘Theory’ in Digital Humanities Journals.” Journal of Cultural Analytics 7, no. 4 (December 19, 2022). https://doi.org/10.22148/001c.55507
- Code for Conceptual Forays https://github.com/theory-in-dh/conceptual_forays
- Sinykin, Dan, and Edwin Roland. “Against Conglomeration.” Journal of Cultural Analytics 6, no. 2 (April 20, 2021). https://doi.org/10.22148/001c.22331
- Sinykin, Daniel; Edwin Roland, 2021, “Replication Data for: Against Conglomeration”, https://doi.org/10.7910/DVN/EUPMKL, Harvard Dataverse, V1
- McNulty, Tess. “Content-Era Ethics.” Journal of Cultural Analytics 6, no. 2 (April 20, 2021). https://doi.org/10.22148/001c.22220
- Mcnulty, Tess, 2021, “Replication Data for: Content-Era Ethics”, https://doi.org/10.7910/DVN/S3DFCU, Harvard Dataverse, V1
- Mullen, Lincoln A. America’s Public Bible: A Commentary. Stanford University Press, 2023. https://americaspublicbible.supdigital.org
- Code for America’s Public Bible https://github.com/lmullen/americas-public-bible
- Funk, Kellen, and Lincoln A. Mullen. “The Spine of American Law: Digital Text Analysis and U.S. Legal Practice (Annotated Version),” 2021. https://doi.org/10.31835/ma.2021.07
- Code for The Spine of American Law https://github.com/lmullen/civil-procedure-codes/
- Cheng, Jonathan. “Fleshing Out Models of Gender in English-Language Novels (1850 – 2000).” Journal of Cultural Analytics 5, no. 1 (January 29, 2020). https://doi.org/10.22148/001c.11652
- Cheng, Jonathan, 2020, “Replication Data for: Fleshing Out Models of Gender in English-Language Novels”, https://doi.org/10.7910/DVN/QUGW8V, Harvard Dataverse, V1
- Soni, Sandeep, Lauren F. Klein, and Jacob Eisenstein. “Abolitionist Networks: Modeling Language Change in Nineteenth-Century Activist Newspapers.” Journal of Cultural Analytics 6, no. 1 (January 18, 2021). https://doi.org/10.22148/001c.18841
- Code for Abolitionist Networks https://github.com/sandeepsoni/semantic-leadership-network
- Underwood, Ted, Kevin Kiley, Wenyi Shang, and Stephen Vaisey. “Cohort Succession Explains Most Change in Literary Culture.” Sociological Science 9 (May 2, 2022): 184–205. https://doi.org/10.15195/v9.a8
- Code for Cohort Succession https://github.com/tedunderwood/period-cohort
- Vicinanza, Paul, Amir Goldberg, and Sameer B Srivastava. “A Deep-Learning Model of Prescient Ideas Demonstrates That They Emerge from the Periphery.” PNAS Nexus 2, no. 1 (January 1, 2023): pgac275. https://doi.org/10.1093/pnasnexus/pgac275
- Code for Prescient Ideas https://github.com/pvicinanza/prescience
- Arnold, Taylor, and Lauren Tilton. “Distant Viewing: Analyzing Large Visual Corpora.” Digital Scholarship in the Humanities 34, no. Supplement_1 (December 1, 2019): i3–16. https://doi.org/10.1093/llc/fqz013
- Code for Distant Viewing https://github.com/distant-viewing/dvt
- Arnold, Taylor, Lauren Tilton, and Annie Berke. “Visual Style in Two Network Era Sitcoms.” Journal of Cultural Analytics 4, no. 2 (July 19, 2019). https://doi.org/10.22148/16.043
- Arnold, Taylor, 2019, “Replication data for: “A Visual Style in Two Network Sitcoms” by Taylor Arnold, Lauren Tilton, and Annie Berke.”, https://doi.org/10.7910/DVN/S84TSX, Harvard Dataverse, V1
- Koeser, Rebecca Sutton, and Zoe LeBlanc. “Missing Data, Speculative Reading.” Journal of Cultural Analytics, vol. 9, no. 2, May 2024, https://doi.org/10.22148/001c.116926
- Code and data used for this article is accessible on https://github.com/rlskoeser/shxco-missingdata-specreading.
- Henley, Amanda, Lorin Bruckner, Hannah Jacobs, Matthew Jansen, Brianna Nunez, Rolando Rodriguez, and Morgan Wilson. “On the Books: Jim Crow and Algorithms of Resistance, a Collections as Data Case Study.” ACM J. Comput. Cult. Herit. 16, no. 4 (January 8, 2024): 85:1-85:20. https://doi.org/10.1145/3631128.
- Code and data used for this article is accessible on [https://github.com/UNC-Libraries-data/OnTheBooks](https://github.com/UNC-Libraries-data/OnTheBooks0.